2008-03-20 SQLiteで全文検索システムを実装する
SQLiteで,掲示板の投稿文に対する日本語全文検索システムを実装することにしました。全文検索はかなり奥が深く,難易度の高い分野です。決して簡単ではありません。
検索対象の情報量が少ないのならさほど苦労しないのですよ。全情報をメモリに読み込んで,逐次検索すればよいのです。ところが全体をメモリに読み込むことができないくらい大容量の情報を扱う場合,なんらかの方法で「索引付け」をしなければ,探し出すのが難しくなってしまいます。
たとえば,「アルファベット順に並んでいない英和辞書」があったとします。これを使って単語を調べなければならないとしたら,どうでしょうか。大変なことになりそうですよね。単語がアルファベットの逆順に並んでいるのならまだ救い様がありそうですが,「てきとー」に並べられている辞書だとしたら,そんなの使い物になりません。
コンピュータの世界でも考え方は同じです。全文検索するためには,まず情報に索引付けしなければならないのです。ところで,ほとんどすべての商業RDBMSには全文検索のための仕組みが備わっているらしいのですが,今回使うのはSQLiteです。SQLiteにはそんな凝った機能ありませんので,自力で実装しなければなりません。どうすれば良いのでしょうか。そもそもSQLiteにそんなことをやらせて,大丈夫なのでしょうか。
N gramによる全文検索
全文検索における索引付けの方法としてよく使われるのは,「形態素解析」と「N gram」です。今回はN gramを使って全文検索することにしました。業界の人ならおそらく「N gram」と聞いただけで,ピンときたはずです。
ピンと来なかった人のために,ちょっと説明しておきますね。「N gram」のNには任意の数値が入ります。普通は「1 gram」「2 gram」という言い方をします。たとえば「あべまりあ」を2 gramに分割してみましょう。分割した結果は,「あべ」「べま」「まり」「りあ」となります。
「こんな意味不明な単語に分けて,どうして全文検索できるのか分からない」と思った人がいるかもしれません。端折って説明すると,分割した語が使われている位置(記事番号)を記録しておくのです。検索するときはまず分割した語を探して,つぎに分割した語が使われている記事を引き出すのです。
さて,上記の例では「あべまりあ」という平仮名だけが使われた文を考えてみました。現実の日本語文章には,さまざまな文字が使われています。普通,文字の種類に応じて文字の分割数を変えるものなのです。
今回は以下の決まりにしてみました。
- 漢字 ― 1 gram
- ひらがな ― 2 gram
- カタカナ― 2 gram
上記のルールで,「吾輩は猫である名前はまだない」という文をN gramに分解してみましょう。「吾」「輩」「猫」「であ」「ある」「名」「前」「はま」「まだ」「だな」「ない」となります。これらを索引情報としてデータベースに登録しておきます。
今回の方法では品詞を無視します。「名前はまだ」を検索したいときに「はま」と検索する人はいないでしょうが,索引情報には「はま」も登録してしまいます。
リンク表
おそらく飽きずにここまで読み進めた人は,さらなる疑問が湧いているはずです。とりわけリレーショナル・データベースを使ったことがある人なら「N gramに分割した語って,重複だらけになるじゃないのよ」と思うはずなのです。
たとえば以下のみっつの文をN gramに分割してデータベースに登録するとします。
- No.1 「吾輩は猫である名前はまだない」
- No.2 「私は猫が大好きです」
- No.3 「お父さんは犬です名前はカイ」
分割後の語の種類はたくさんありますが,簡単にするために「猫」「名」「です」「犬」だけに注目することにしましょう。索引情報を作りたいのなら,以下の情報を登録できればよいのです。
- 「猫」 → No.1とNo.2
- 「名」 → No.1とNo.3
- 「です」 → No.2とNo.3
- 「犬」 → No.3
ところでリレーショナル・データベースでは,上記のような「列(属性)数が不定個」といったデータ構造を普通は扱いません(普通じゃないときには扱ってしまうこともあります←なぞ)。実際は以下のように格納することになります。ところがこのままではまだ不足なのです。
- 「猫」 → No.1
- 「猫」 → No.2
- 「名」 → No.1
- 「名」 → No.3
- 「です」 → No.2
- 「です」 → No.3
- 「犬」 → No.3
問題になるのは情報量です。SQLiteでは普通,文字列のエンコードにはUTF-8が使われます。日本語2文字の場合UTF-8では6バイト消費してしまうのです。単純に考えて日本語の場合だと「です」という単語が膨大な数,登録されてしまいそうです。容量を節約する方法はないのでしょうか。
素直な考え方として,表を正規化すれば容量を節約できます。分割した語から直接,記事を指し示すのではなく間に「リンク表」を挟むことにするのです。リンク表の列には,「ID値」と「記事番号値」を持たせます。
表の関係を図示すると以下のようになります。
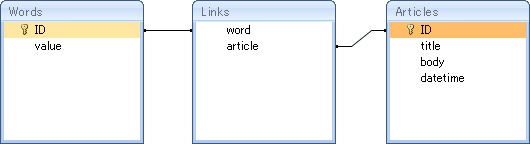
ここまで話を引っ張っておいて,手の平を返すようですが今回の場合,正規化の恩恵はあまりありません。分割後の語の容量は最長で6バイトですが,ディスクの性能によっては容量の増大が問題にならないのかもしれません。その場合,正規化はむしろ有害に働く可能性があります。今回,扱う情報は不変の事実であって,あとで修正されることはありえないのです。たとえば投稿文に「犬」という単語があったとします。それが後に「猫」に修正されることはありません。
SQLクエリ
ようやくSQLの話になります。索引情報を構築するまでは分かったとして,実際にどうやってSQLで記事を検索するというのでしょうか。
データベースに格納した索引情報は,「集合」の要素そのものです。どういう意味なのかというと,数学的には集合演算でいう「積集合」を求めれば良いのです。リレーショナル・データベースは構造上,集合演算が得意でありSQLにも都合の良い演算子が用意されています。
仮に「名前」というキーワードの含まれた記事を検索することにしましょう。まずキーワード自身をN gramに分割します。分割すると「名」「前」となります。つぎに語の出現頻度に対して,語を昇順に並び替えます。語を並び替える理由は,処理効率を良くするためです。数学的には集合の要素は順序を問いませんので,並び替える必要はありません。でも実在するコンピュータで計算させるためには,計算量が少なくなるような工夫をしておかないと,処理効率が悪くなってしまうのです。
SQLiteにはINTERSECTという積集合を求める演算子が用意されています。各語に対してレコードを抽出し,抽出したレコードが指す記事番号の積集合を計算していきます。多少の「揺らぎ」を持たせるためにLIKEで抽出します。たとえば以下のようなSQLになります。
SELECT id, domain, root, no, created, deleted, title, autor, body, ua, host
FROM
(
SELECT article
FROM
(
SELECT t2.article AS article
FROM
(
SELECT id
FROM words
WHERE value LIKE ?
) AS t1
INNER JOIN
links AS t2
ON t1.id = t2.word
)
INTERSECT
SELECT article
FROM
(
SELECT t2.article AS article
FROM
(
SELECT id
FROM words
WHERE value LIKE ?
) AS t1
INNER JOIN
links AS t2
ON t1.id = t2.word
)
) AS t1
INNER JOIN
article AS t2
ON t1.article = t2.id
ORDER BY
root DESC, no
「value LIKE ?」の「?」はプレースホルダです。「?」の個所が,任意の「語」に置き換わるわけです。
最後に
全文検索は非常に奥が深いため,重点となる話題だけをお話しました。
最後に,崖から落っこちるようなことを言ってしまいますよ。今回の方法は,SQLiteには不適だったようです。20万件の投稿文に対して検索させてみましたが,処理速度は遅くないものの索引情報が大きくなりすぎる気がしました。私の設計がマズイからというのが最大の原因でしょうけれど,そもそもSQLiteにやらせてはいけない仕事のような気がしました。
以下,大切なんだけれど漏れてしまったお話を少々。
- 揺れの除去 ― 全文検索で問題になるのは日本語の「揺れ」です。たとえば「フィルム」と言ったり「フイルム」と言ったり,「ボディ」と言ったり「ボデー」と言ったりします。これからを同じコトバとして検索させるため,あらかじめ表記を標準化しておかなければなりません
- 形態素解析とN gram ― じつは過去に形態素解析を使ったバージョンを同じくSQLiteで実装したことがあります。形態素解析は未知語に弱いのですが,N gramは検索漏れがほとんどありません。掲示板の投稿文は言葉遣いがめちゃくちゃなことが多々ありますので,N gramの方が向いていると思います。しかし,索引情報が大きすぎるというわけで,世の中うまくいかないものですね