 yumi-ii
yumi-ii2010-10-28 Seesaaブログ/さくらのブログ絵文字,携帯3キャリア対応表
【注意】このページは,IE8以降のブラウザで開いてください。IE7以前では画像が正しく表示されません。このページのコンテンツには,Dataスキーム(DataURI)によるインライン画像が含まれているためです。
2010年10月21日,さくらのブログがバージョンアップしました。
ブログのバージョンアップによって,大掛かりな仕様変更がいくつかありました。この文章は,その中のSeesaa絵文字の変換ルールに関する情報を扱います。(さくらのブログには,Seesaaブログと同じCMS(Contents Management System,コンテンツマネジメントシステム)が導入されています。さくらのブログとSeesaaブログは,同じものです。)
ブログ記事を携帯電話(iモードやEZweb)で開くと,Seesaa絵文字が携帯電話各社の絵文字に変換されるのですが,思ったように変換してくれない絵文字がいくつかありました。
狙いどおりのコンテンツを出力させるために,絵文字の対応表を作ってみることにしました。
注意事項
このページの情報には,何らの保証もありません。絵文字の変換表は,独自に調査したものです。公式なものではありません。
Seesaaブログ/さくらのブログ絵文字:携帯3キャリア対応表
ブログの記事を携帯電話で開いたときの,絵文字の対応表です。
変換の方向は,「Seesaa絵文字→携帯絵文字」です。携帯電話から記事やコメントを投稿すると,「携帯絵文字→Seesaa絵文字」という(逆方向の)変換も発生するのですが,この表では対象外です。
| 値(SJIS, 10進数) | Seesaa絵文字 | docomo | au | SoftBank |
|---|---|---|---|---|
|  |  |
 |
 |
|
|  |  |
 |
 |
|
|  |  |
 |
 |
|
|  |  |
 |
 |
|
|  |  |
 |
 |
|
|  |  |
 |
 |
|
|  |  |
 |
[霧] | |
|  |  |
 |
 |
|
|  |  |
 |
 |
|
|  |  |
 |
 |
|
|  |  |
 |
 |
|
|  |  |
 |
 |
|
|  |  |
 |
 |
|
|  |  |
 |
 |
|
|  |  |
 |
 |
|
|  |  |
 |
 |
|
|  |  |
 |
 |
|
|  |  |
 |
 |
|
|  |  |
 |
 |
|
|  |  |
 |
 |
|
|  |  |
〓 | 〓 | |
|  |  |
 |
 |
|
|  |  |
 |
 |
|
|  |  |
 |
 |
|
|  |  |
 |
 |
|
|  |  |
 |
 |
|
|  |  |
 |
 |
|
|  |  |
 |
 |
|
|  |  |
 |
[ポケベル] | |
|  |  |
 |
 |
|
|  |  |
 |
 |
|
|  |  |
 |
 |
|
|  |  |
 |
 |
|
|  |  |
|
 |
|
|  |  |
 |
 |
|
|  |  |
 |
 |
|
|  |  |
 |
 |
|
|  |  |
 |
 |
|
|  |  |
 |
 |
|
|  |  |
 |
 |
|
|  |  |
 |
 |
|
|  |  |
 |
 |
|
|  |  |
 |
 |
|
|  |  |
 |
 |
|
|  |  |
 |
 |
|
|  |  |
 |
 |
|
|  |  |
 |
 |
|
|  |  |
 |
 |
|
|  |  |
 |
 |
|
|  |  |
 |
 |
|
|  |  |
 |
 |
|
|  |  |
 |
 |
|
|  |  |
 |
 |
|
|  |  |
 |
 |
|
|  |  |
 |
 |
|
|  |  |
 |
 |
|
|  |  |
 |
 |
|
|  |  |
 |
 |
|
|  |  |
 |
 |
|
|  |  |
〓 | 〓 | |
|  |  |
 |
 |
|
|  |  |
 |
 |
|
|  |  |
 |
 |
|
|  |  |
 |
〓 | |
|  |  |
 |
 |
|
|  |  |
 |
 |
|
|  |  |
 |
 |
|
|  |  |
 |
 |
|
|  |  |
 |
 |
|
|  |  |
 |
 |
|
|  |  |
 |
 |
|
|  |  |
 |
 |
|
|  |  |
 |
 |
|
|  |  |
 |
 |
|
|  |  |
 |
 |
|
|  |  |
 |
 |
|
|  |  |
 |
 |
|
|  |  |
 |
[ゲーム] | |
|  |  |
 |
 |
|
|  |  |
 |
 |
|
|  |  |
 |
 |
|
|  |  |
 |
 |
|
|  |  |
 |
 |
|
|  |  |
 |
 |
|
|  |  |
 |
 |
|
|  |  |
 |
 |
|
|  |  |
 |
 |
|
|  |  |
 |
 |
|
|  |  |
 |
 |
|
|  |  |
 |
 |
|
|  |  |
 |
 |
|
|  |  |
 |
 |
|
|  |  |
 |
[メガネ] | |
|  |  |
 |
 |
|
| 鹿 |  |
 |
● | |
| 論 |  |
 |
 |
|
| 壟 |  |
 |
|
|
| 弄 |  |
 |
|
|
| 籠 |  |
○ | ○ | |
| 聾 |  |
 |
 |
|
| 牢 |  |
 |
 |
|
| 磊 |  |
 |
 |
|
| 賂 |  |
 |
 |
|
| 雷 |  |
 |
 |
|
| 縷 |  |
 |
 |
|
| 陋 |  |
[ふくろ] | [ふくろ] | |
| 勒 |  |
 |
[ペン] | |
| 凌 |  |
〓 | 〓 | |
| 稜 |  |
[いす] |  |
|
| 綾 |  |
 |
 |
|
| 拏 |  |
[SOON] | [SOON] | |
| 樂 |  |
[ON] | [ON] | |
| 諾 |  |
[end] | [end] | |
| 丹 |  |
 |
 |
|
| 沈 |  |
 |
 |
|
| 拾 |  |
 |
 |
|
| 若 |  |
 |
 |
|
| 掠 |  |
[iモード] | [iモード] | |
| 略 |  |
[iモード] | [iモード] | |
| 亮 |  |
 |
|
|
| 兩 |  |
[ドコモ] | [ドコモ] | |
| 凉 |  |
[ドコモポイント] | [ドコモポイント] | |
| 梁 |  |
 |
¥ | |
| 糧 |  |
 |
[FREE] | |
| 良 |  |
 |
 |
|
| 諒 |  |
 |
 |
|
| 量 |  |
 |
〓 | |
| 呂 |  |
 |
[CL] | |
| 女 |  |
 |
 |
|
| 廬 |  |
 |
 |
|
| 旅 |  |
 |
〓 | |
| 濾 |  |
[フリーダイヤル] |  |
|
| 礪 |  |
 |
 |
|
| 閭 |  |
 |
[Q] | |
| 驪 |  |
 |
 |
|
| 麗 |  |
 |
 |
|
| 黎 |  |
 |
 |
|
| 力 |  |
 |
 |
|
| 曆 |  |
 |
 |
|
| 歷 |  |
 |
 |
|
| 轢 |  |
 |
 |
|
| 年 |  |
 |
 |
|
| 憐 |  |
 |
 |
|
| 戀 |  |
 |
 |
|
| 撚 |  |
 |
 |
|
| 漣 |  |
 |
 |
|
| 煉 |  |
 |
 |
|
| 璉 |  |
 |
|
|
| 秊 |  |
 |
 |
|
| 練 |  |
 |
 |
|
| 聯 |  |
 |
 |
|
| 輦 |  |
 |
 |
|
| 蓮 |  |
 |
 |
|
| 連 |  |
 |
|
|
| 鍊 |  |
 |
 |
|
| 列 |  |
 |
 |
|
| 劣 |  |
〓 | 〓 | |
| 咽 |  |
 |
 |
|
| 烈 |  |
 |
 |
|
| 裂 |  |
 |
 |
|
| 說 |  |
 |
 |
|
| 廉 |  |
 |
 |
|
| 念 |  |
 |
 |
|
| 捻 |  |
 |
 |
|
| 殮 |  |
 |
|
|
| 簾 |  |
 |
 |
|
| 獵 |  |
 |
 |
|
| 令 |  |
 |
!? | |
| 囹 |  |
 |
!! | |
| 寧 |  |
 |
〓 | |
| 嶺 |  |
 |
 |
|
| 怜 |  |
 |
|
|
| 玲 |  |
 |
 |
|
| 瑩 |  |
〓 | 〓 | |
| 羚 |  |
 |
〓 | |
| 聆 |  |
 |
 |
|
| 鈴 |  |
[iアプリ] | [iアプリ] | |
| 零 |  |
[iアプリ] | [iアプリ] | |
| 靈 |  |
 |
 |
|
| 領 |  |
 |
[財布] | |
| 例 |  |
 |
 |
|
| 禮 |  |
 |
[ジーンズ] | |
| 醴 |  |
 |
[スノボ] | |
| 隸 |  |
 |
 |
|
| 惡 |  |
[ドア] | [ドア] | |
| 了 |  |
 |
 |
|
| 僚 |  |
 |
 |
|
| 寮 |  |
 |
|
|
| 尿 |  |
 |
[レンチ] | |
| 料 |  |
 |
|
|
| 樂 |  |
 |
 |
|
| 燎 |  |
 |
 |
|
| 療 |  |
 |
[砂時計] | |
| 蓼 |  |
 |
 |
|
| 遼 |  |
 |
 |
|
| 龍 |  |
 |
[腕時計] | |
| 暈 |  |
|
 |
|
| 阮 |  |
 |
 |
|
| 劉 |  |
|
 |
|
| 杻 |  |
 |
 |
|
| 柳 |  |
 |
 |
|
| 流 |  |
 |
 |
|
| 溜 |  |
 |
 |
|
| 琉 |  |
 |
 |
|
| 留 |  |
 |
 |
|
| 硫 |  |
 |
 |
|
| 紐 |  |
|
|
|
| 類 |  |
 |
|
|
| 六 |  |
 |
 |
|
| 戮 |  |
 |
 |
|
| 陸 |  |
 |
 |
|
| 倫 |  |
[NG] | [NG] | |
| 崙 |  |
 |
[クリップ] | |
| 淪 |  |
 |
 |
|
| 輪 |  |
 |
 |
|
| 律 |  |
 |
 |
|
| 慄 |  |
 |
 |
|
| 栗 |  |
 |
〓 | |
| 率 |  |
 |
 |
|
| 隆 |  |
 |
 |
|
| 利 |  |
[禁] | [禁] | |
| 吏 |  |
 |
 |
|
| 履 |  |
[合] | [合] | |
| 易 |  |
 |
 |
|
| 李 |  |
 |
⇔ | |
| 梨 |  |
 |
↑↓ | |
| 泥 |  |
 |
 |
|
| 理 |  |
 |
 |
|
| 痢 |  |
 |
 |
|
| 罹 |  |
 |
 |
|
| 裏 |  |
 |
[チェリー] | |
| 裡 |  |
 |
 |
|
| 里 |  |
 |
[バナナ] | |
| 離 |  |
 |
 |
|
| 匿 |  |
 |
|
|
| 溺 |  |
 |
 |
|
| 吝 |  |
 |
 |
|
| 燐 |  |
 |
 |
|
| 璘 |  |
 |
 |
|
| 藺 |  |
 |
 |
|
| 隣 |  |
 |
 |
|
| 鱗 |  |
 |
 |
|
| 麟 |  |
 |
[カタツムリ] | |
| 林 |  |
 |
 |
|
| 淋 |  |
 |
 |
|
| 臨 |  |
|
 |
|
| 立 |  |
 |
 |
|
| 笠 |  |
 |
 |
|
| 粒 |  |
 |
 |
|
| 狀 |  |
 |
 |
|
| 炙 |  |
 |
|
|
| 識 |  |
 |
 |
関連リンク
2008-12-23 iモードブラウザの表示文字数―1行を何文字にしていますか―
携帯サイトのお話です。iモードブラウザの画面当たりの表示文字数や,フォントの大きさなどを調べてみました。
結果発表
いきなり結果発表です。
- 表示文字数は「半角24×16文字」がいちばん多い(全角文字に換算すると12×16文字)
- フォントの大きさは「デフォルト設定」の人が多い
というわけで,買った直後の状態のまま使っている人が大半だということが分かりました。
この結果はiモードブラウザの表示文字数ですので,auやSoftbankのことは分かりません。でもauやSoftbankの利用者やブラウザの仕様が,docomoと極端に違うわけではないでしょうから,そのままauやSoftbankに当てはめてしまっても問題はないと思います。
つぎに調査方法の概要と,結果の詳細をお話します。
調査の方法
私が運用している,某携帯サイトのアクセスログから標本を抽出しました。以下は集計方法の概要です。
- 集計期間:2008年9月から同年11月の3か月間
- 標本数:24,026件
- 対象キャリア:docomoのみ
- 利用者年齢:平均33.6歳
- 性別構成:不明
なお,同じユーザエージェントが1時間以内に何度も観測された場合は,出現件数をまとめて1件としました。利用者がなるべく重複しないようにするための処置です。
画面情報の傾向
(1)画面の表示文字数
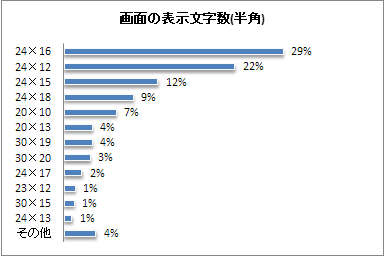
<説明>ユーザエージェントから,画面の横幅と縦幅(ブラウザ表示可能バイト数)を調べてみました。「24x16」がいちばん多いことが分かりました。サイトを作るときは,横の文字数は半角24文字,縦の文字数は16文字を頭に入れておけば良さそうです。iモードHTMLシミュレーターで表示確認するときに,「サイズ設定画面」の表示サイズを「12x16」に指定しておけば良いのです。
(2)画面の横幅
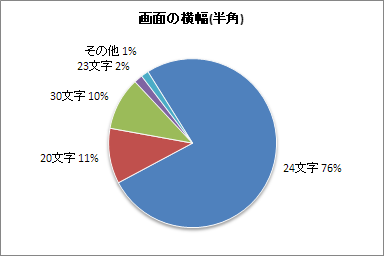
<説明>画面の横幅だけに注目すると,「半角24文字」が全体の76%を占めました。半角20文字未満の機種を使っている人は,ほとんど存在しないことが分かりました。
(3)ブラウザのフォントサイズ
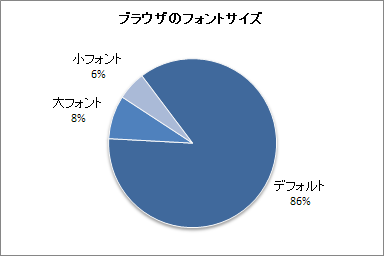
<説明>P905i(2,099件),SH906i(1,780件)を対象に(この2機種は出現頻度1位と2位です),利用者が設定しているフォントの大きさを調べました。「デフォルト設定」のまま使っている人が多いことが分かりました。「P905i,SH906i以外の機種は集計していないけれど,問題ないの?」と思った人がいるかもしれません。P905i,SH906iだけで全体の16%(3,879/24,026)を網羅できました。これが多いのか少ないのか,標本数の過不足の判断は各自にお任せします。
(4)画像表示のON/OFF
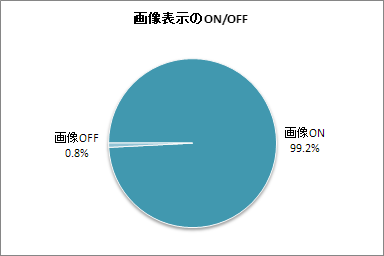
<説明>画像表示をONにしているか,OFFにしているのか調べてみました。大多数の人が「ONのまま」使っていることが分かりました。画像をOFFにしている人は,ほとんど存在しませんでした。
集計方法を凝る必要はなかった
今後のお話です。
今回は,HTTPのアクセスログから表示文字数やフォントの大きさなどを調べました。どうやら,アクセスログを持ち出す必要はなかったようです。調査する時点でいちばん売れている機種を調べて,その機種の表示文字数を把握するだけで十分みたいですね。
関連リンク
2008-03-20 SQLiteで全文検索システムを実装する
SQLiteで,掲示板の投稿文に対する日本語全文検索システムを実装することにしました。全文検索はかなり奥が深く,難易度の高い分野です。決して簡単ではありません。
検索対象の情報量が少ないのならさほど苦労しないのですよ。全情報をメモリに読み込んで,逐次検索すればよいのです。ところが全体をメモリに読み込むことができないくらい大容量の情報を扱う場合,なんらかの方法で「索引付け」をしなければ,探し出すのが難しくなってしまいます。
たとえば,「アルファベット順に並んでいない英和辞書」があったとします。これを使って単語を調べなければならないとしたら,どうでしょうか。大変なことになりそうですよね。単語がアルファベットの逆順に並んでいるのならまだ救い様がありそうですが,「てきとー」に並べられている辞書だとしたら,そんなの使い物になりません。
コンピュータの世界でも考え方は同じです。全文検索するためには,まず情報に索引付けしなければならないのです。ところで,ほとんどすべての商業RDBMSには全文検索のための仕組みが備わっているらしいのですが,今回使うのはSQLiteです。SQLiteにはそんな凝った機能ありませんので,自力で実装しなければなりません。どうすれば良いのでしょうか。そもそもSQLiteにそんなことをやらせて,大丈夫なのでしょうか。
N gramによる全文検索
全文検索における索引付けの方法としてよく使われるのは,「形態素解析」と「N gram」です。今回はN gramを使って全文検索することにしました。業界の人ならおそらく「N gram」と聞いただけで,ピンときたはずです。
ピンと来なかった人のために,ちょっと説明しておきますね。「N gram」のNには任意の数値が入ります。普通は「1 gram」「2 gram」という言い方をします。たとえば「あべまりあ」を2 gramに分割してみましょう。分割した結果は,「あべ」「べま」「まり」「りあ」となります。
「こんな意味不明な単語に分けて,どうして全文検索できるのか分からない」と思った人がいるかもしれません。端折って説明すると,分割した語が使われている位置(記事番号)を記録しておくのです。検索するときはまず分割した語を探して,つぎに分割した語が使われている記事を引き出すのです。
さて,上記の例では「あべまりあ」という平仮名だけが使われた文を考えてみました。現実の日本語文章には,さまざまな文字が使われています。普通,文字の種類に応じて文字の分割数を変えるものなのです。
今回は以下の決まりにしてみました。
- 漢字 ― 1 gram
- ひらがな ― 2 gram
- カタカナ― 2 gram
上記のルールで,「吾輩は猫である名前はまだない」という文をN gramに分解してみましょう。「吾」「輩」「猫」「であ」「ある」「名」「前」「はま」「まだ」「だな」「ない」となります。これらを索引情報としてデータベースに登録しておきます。
今回の方法では品詞を無視します。「名前はまだ」を検索したいときに「はま」と検索する人はいないでしょうが,索引情報には「はま」も登録してしまいます。
リンク表
おそらく飽きずにここまで読み進めた人は,さらなる疑問が湧いているはずです。とりわけリレーショナル・データベースを使ったことがある人なら「N gramに分割した語って,重複だらけになるじゃないのよ」と思うはずなのです。
たとえば以下のみっつの文をN gramに分割してデータベースに登録するとします。
- No.1 「吾輩は猫である名前はまだない」
- No.2 「私は猫が大好きです」
- No.3 「お父さんは犬です名前はカイ」
分割後の語の種類はたくさんありますが,簡単にするために「猫」「名」「です」「犬」だけに注目することにしましょう。索引情報を作りたいのなら,以下の情報を登録できればよいのです。
- 「猫」 → No.1とNo.2
- 「名」 → No.1とNo.3
- 「です」 → No.2とNo.3
- 「犬」 → No.3
ところでリレーショナル・データベースでは,上記のような「列(属性)数が不定個」といったデータ構造を普通は扱いません(普通じゃないときには扱ってしまうこともあります←なぞ)。実際は以下のように格納することになります。ところがこのままではまだ不足なのです。
- 「猫」 → No.1
- 「猫」 → No.2
- 「名」 → No.1
- 「名」 → No.3
- 「です」 → No.2
- 「です」 → No.3
- 「犬」 → No.3
問題になるのは情報量です。SQLiteでは普通,文字列のエンコードにはUTF-8が使われます。日本語2文字の場合UTF-8では6バイト消費してしまうのです。単純に考えて日本語の場合だと「です」という単語が膨大な数,登録されてしまいそうです。容量を節約する方法はないのでしょうか。
素直な考え方として,表を正規化すれば容量を節約できます。分割した語から直接,記事を指し示すのではなく間に「リンク表」を挟むことにするのです。リンク表の列には,「ID値」と「記事番号値」を持たせます。
表の関係を図示すると以下のようになります。
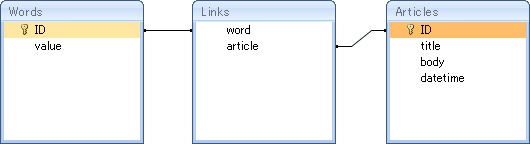
ここまで話を引っ張っておいて,手の平を返すようですが今回の場合,正規化の恩恵はあまりありません。分割後の語の容量は最長で6バイトですが,ディスクの性能によっては容量の増大が問題にならないのかもしれません。その場合,正規化はむしろ有害に働く可能性があります。今回,扱う情報は不変の事実であって,あとで修正されることはありえないのです。たとえば投稿文に「犬」という単語があったとします。それが後に「猫」に修正されることはありません。
SQLクエリ
ようやくSQLの話になります。索引情報を構築するまでは分かったとして,実際にどうやってSQLで記事を検索するというのでしょうか。
データベースに格納した索引情報は,「集合」の要素そのものです。どういう意味なのかというと,数学的には集合演算でいう「積集合」を求めれば良いのです。リレーショナル・データベースは構造上,集合演算が得意でありSQLにも都合の良い演算子が用意されています。
仮に「名前」というキーワードの含まれた記事を検索することにしましょう。まずキーワード自身をN gramに分割します。分割すると「名」「前」となります。つぎに語の出現頻度に対して,語を昇順に並び替えます。語を並び替える理由は,処理効率を良くするためです。数学的には集合の要素は順序を問いませんので,並び替える必要はありません。でも実在するコンピュータで計算させるためには,計算量が少なくなるような工夫をしておかないと,処理効率が悪くなってしまうのです。
SQLiteにはINTERSECTという積集合を求める演算子が用意されています。各語に対してレコードを抽出し,抽出したレコードが指す記事番号の積集合を計算していきます。多少の「揺らぎ」を持たせるためにLIKEで抽出します。たとえば以下のようなSQLになります。
SELECT id, domain, root, no, created, deleted, title, autor, body, ua, host
FROM
(
SELECT article
FROM
(
SELECT t2.article AS article
FROM
(
SELECT id
FROM words
WHERE value LIKE ?
) AS t1
INNER JOIN
links AS t2
ON t1.id = t2.word
)
INTERSECT
SELECT article
FROM
(
SELECT t2.article AS article
FROM
(
SELECT id
FROM words
WHERE value LIKE ?
) AS t1
INNER JOIN
links AS t2
ON t1.id = t2.word
)
) AS t1
INNER JOIN
article AS t2
ON t1.article = t2.id
ORDER BY
root DESC, no
「value LIKE ?」の「?」はプレースホルダです。「?」の個所が,任意の「語」に置き換わるわけです。
最後に
全文検索は非常に奥が深いため,重点となる話題だけをお話しました。
最後に,崖から落っこちるようなことを言ってしまいますよ。今回の方法は,SQLiteには不適だったようです。20万件の投稿文に対して検索させてみましたが,処理速度は遅くないものの索引情報が大きくなりすぎる気がしました。私の設計がマズイからというのが最大の原因でしょうけれど,そもそもSQLiteにやらせてはいけない仕事のような気がしました。
以下,大切なんだけれど漏れてしまったお話を少々。
- 揺れの除去 ― 全文検索で問題になるのは日本語の「揺れ」です。たとえば「フィルム」と言ったり「フイルム」と言ったり,「ボディ」と言ったり「ボデー」と言ったりします。これからを同じコトバとして検索させるため,あらかじめ表記を標準化しておかなければなりません
- 形態素解析とN gram ― じつは過去に形態素解析を使ったバージョンを同じくSQLiteで実装したことがあります。形態素解析は未知語に弱いのですが,N gramは検索漏れがほとんどありません。掲示板の投稿文は言葉遣いがめちゃくちゃなことが多々ありますので,N gramの方が向いていると思います。しかし,索引情報が大きすぎるというわけで,世の中うまくいかないものですね
2007-11-09 XMLRPC::Liteで“さくらのブログ”に記事を投稿する
XML-RPCを使って「さくらのブログ」に記事を投稿するコードを作りました。
あらまし
普通,ブログに記事を投稿するにはWebブラウザで管理画面を開いて,フォームに記事を入力しなければなりません。XML-RPC(いわゆるブログAPI)を使うと,Webの管理画面を使わなくても記事を投稿できます。
動作概要
- PerlのXMLRPC::Liteモジュールを使う
- 新規記事を投稿するAPIには数種類あるが,今回は「metaWeblog.newPost」を使う
- 「さくらのブログ」「Seesaaブログ」に対応。ほかの商業ブログもだいたい同じはず。ただし動作確認した環境は「さくらのブログ」のみ
コード
use strict ;
use XMLRPC::Lite trace => 'debug' ;
use Encode ;
use encoding 'utf8' ;
#####
my $blogid = '123456' ;
my $username = 'username.sakura.ne.jp' ;
my $password = '********' ;
my $content = {
title => Encode::encode( 'utf8', '件名' ),
description => Encode::encode( 'utf8', '本文' ),
mt_text_more => Encode::encode( 'utf8', '追記' ),
dateCreated => '2007-01-01T00:00:00', # ISO8601形式
} ;
my $publish = XMLRPC::Data->type( boolean => 1 ) ;
#####
my $uri = 'http://blog.sakura.ne.jp/rpc/' ;
my $method = 'metaWeblog.newPost' ;
my @params = (
$blogid,
$username,
$password,
$content,
$publish,
) ;
#####
my $result = XMLRPC::Lite->proxy( $uri )->call( $method, @params )->result ;
# $resultにはpostidが入る
if( !$result )
{
die 'ERR' ;
}
注意点
(1) ソースファイルはUTF-8(BOMなし)で保存してください。Windowsの「メモ帳」で保存すると,この条件を満たさないので注意してください。
(2) あらかじめブログの管理画面で「パスワード」を設定しておきます。パスワードが思いつかない方は, 「yumi-ii | パスワード文字列を作る」をお試しください。
メモ
- 日本語を扱う方法 ― XML-RPCの引数に日本語を含めるときは「Encode::encode('utf8', '日本語')」として,UTF-8フラグを外しておきます。UTF-8フラグを外さないと,実行時に「Wide character in subroutine entry at ...」というエラーが発生します
- 未対応の属性 ― 現時点ではconvert_breaksやallow_commentsなどには対応していない模様。対応していない属性は無視されます
- 記事の作成日時 ― dateCreatedを省略すると,現在の日時が記事の作成日時になります
2007-04-22 ExcelからSQLiteのデータベースに接続する
SQLiteのデータベースからExcelの表に株価データを引き出して,チャートを作りたいと思いました。
ExcelからSQLiteを使うには,SQLite用のODBCドライバをインストールすればよいらしい。ODBCドライバのインストールは簡単でした。ところが「外部データの取り込み」をしようとしたら接続時にエラーが発生してしまい,うまくいきませんでした。試行錯誤した結果,接続に成功したので経緯を残しておきます。(「外部データの取り込み」って初めて使ったもので,じつはこの動作で正常なのかもしれません。)
確認環境
- Microsoft Excel 2000(Windows 2000 Professional SP4)
- Microsoft Excel 2003(Windows XP HOME SP2)
- SQLite ODBC Driver 0.74(EXEファイル版)
- SQLite Version 3.2.7 (Windows)で作成したデータベースファイル
環境が違うと再現しないのかもしれません。この業界そういうものです(なぞ)。
再現手順
(1) ODBCドライバのインストール。「SQLite ODBC Driver」のページからEXEファイルをダウンロードし,実行する。
――以後はExcelを起動してからの操作です。
(2) 新規データソースの作成(1/3)。ファイルメニューより「データ(D)→外部データの取り込み(D)→新しいデータベースクエリ(N)」をする。
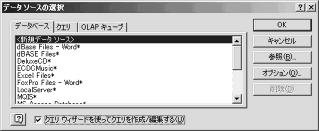
(3) 【画像↑】新規データソースの作成(2/3)。「新規データソース」を選択しOKをクリックする。
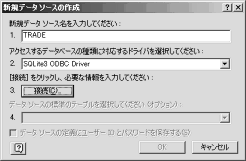
(4) 【画像↑】新規データソースの作成(3/3)。新規データソース名に任意の名前(この例では「TRADE」),ドライバは「SQLite3 ODBC Driver」を選択する。接続(C)をクリックする。
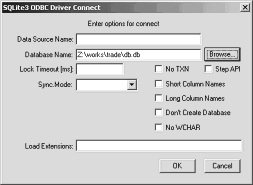
(5) 【画像↑】SQLite3 ODBC Driver Connect。「Database Name」にSQLiteのデータベースファイルを入力する。そのほかの入力項目はひとまず空欄でも問題なさそうです。
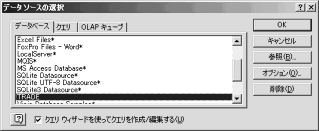
(6) 【画像↑】データソースの選択。データベースの一覧に「TRADE」が現れる。TRADEを選択してOKをクリックする。
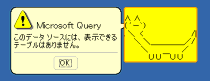
(7) 【画像↑】エラーメッセージ。「このデータソースには、表示できるテーブルはありません。」が表示される。OKをクリックする。
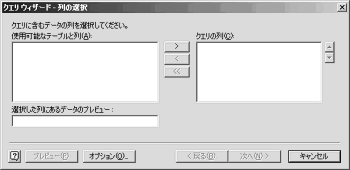
(8) 【画像↑】クエリーウィザード列の選択。たしかにテーブルが空である。オプション(O)をクリックする。
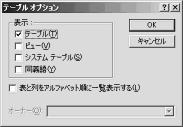
(9) 【画像↑】テーブルオプション。「表示」領域の「テーブル(T),ビュー(V),システムテーブル(S),同義語(Y)」のチェックを外して,OKをクリックする。「クエリーウィザード列の選択」に戻ったらもう一度,オプション(O)をクリックする。今度はテーブル(T)をチェックし,OKをクリックする。
――チェック項目はどれでも構いません。ようはテーブルオプションの更新を通知すればよいみたいです。
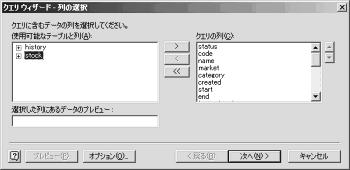
(10) 【画像↑】クエリーウィーザード列の選択。「使用可能なテーブルと列」に「history」と「stock」が表示される(列名はあくまで例です)。
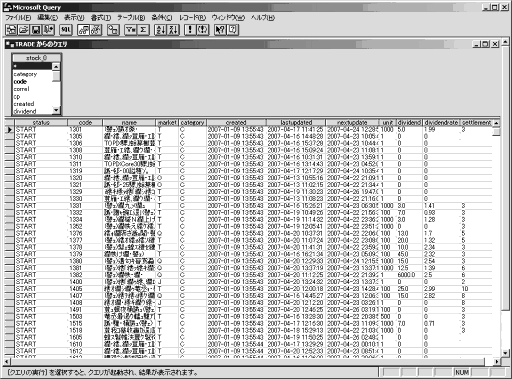
(11) 【画像↑】Microsoft Query。クエリを実行してみたところ結果を得ることができました。Microsoft Queryの画面では日本語が文字化けしていますが,Excelにデータを返すと文字化けは解決されます。
Excel 2007の場合
【追記 21 AUG 2009】リボンより,「データ→外部データの取り込み→その他のデータソース→Microsoft Query」を選びます。以後の手順は,Excel 2000/2003の場合と同じです。注意点として「データ→接続→ブックの接続」を選んではいけません。機能もダイアログの見た目もなんだか似ていますが,データソースを選択した時点で,「このデータソースには表示できるテーブルがありません。」が表示されて先に進めません。
2007-03-28 dbishで/(スラッシュ)を使うには
dbishはPerl-DBI(DataBase Interface)の対話的なコマンド・シェルです。私は専らSQLiteのDBを操作するときに使っています。
さて,dbishでSQL文を発行していると/(スラッシュ)がエラーになってしまうことがあります。例えば,以下のようなコマンドを入力すると
SELECT * FROM t WHERE a < 100/2 ;
「DBD::SQLite::db prepare failed: near "SELECT": syntax error(1) at dbdimp.c line 269, <FIN>line 12.」みたいなエラーが発生します。どうしたら良いのでしょうか。
スラッシュはdbishのメタ文字
どうしてスラッシュがだめなのかというと,スラッシュはdbishのメタ文字だからなのです。普通,SQLではスラッシュを除算記号として扱います。問題が起きる原因は,dbishの内部でSQLとシェルコマンドとの区別が付かなくなるからなのでしょう。「\/」としたり「//」とすればメタ文字をエスケープできそうな気がしたのですが,うまくいきませんでした。
でも回避方法をふたつ見つけたのでお話します。
【回避方法1】runコマンドを使う
まずFILENAMEというファイルを用意します(ファイル名は例なので何でも良いです)。FILENAMEにはあらかじめ実行したいSQL文を書いておきます。
dbishのプロンプトから「/run FILENAME」とすると,dbishはFILENAMEに書かれたSQL文を実行してくれます。FILENAMEの中身はdbishのメタ文字の影響を受けません。
【回避方法2】command_prefixを変更する
dbishのプロンプトから「/option command_prefix=[#]」とするとcommand_prefixを#(番号記号)に替えることができます(番号記号はあくまで例です。好きな記号を使うことができます)。シェル上で入力するSQL文は
SELECT * FROM t WHERE a < 100/2 #
のようになります。たしかにスラッシュが使えるようになるのですが,コマンドの見た目が変かもしれません。気になる方はrunコマンドを使った方がいいでしょう。
2007-01-04 SQLiteで集約関数を追加する
PerlのDBD::SQLiteモジュール環境で,中央値(メディアン<英>Median)関数を使えるようにしてみます。「SQLiteのヘルプを読んだら,関数は追加できるって書いてあったような」と記憶に残っている人もいるはず。どうすれば関数を追加できるのでしょうか。
集約関数とは
SQLiteで使える関数の種類には,単純関数と集約関数の二種類があります。今回,実装するのは集約関数(avg,sumのようにSELECTで抽出した要素に対して作用する関数)です。単純関数の実装方法は説明しませんので注意してください。
中央値とは
念のため「中央値」とは何か,整理しておきます。
<条件>要素は昇順(小から大)に並んでいるものとする。
<定義>要素の個数をnとする。
- nが奇数のとき,ちょうど真ん中の値
- nが偶数のとき,真ん中のふたつの数の平均値
<例>中央値を返す関数Medianがあったとき,関数Medianが返す値は以下のようになる。
Median( 1,2,3,4,5 ) = 3 Median( 1,2,3,4,5,6 ) = 3.5 Median( 1,1,1,1,1,6 ) = 1
Perlによる実装
ようやく実装の話になります。以下,手順です。Perlのオブジェクト指向プログラミングを知らないと解読するのが面倒かもしれませんが,やっていることはさほど複雑ではありません。
- package宣言にて名前空間を指定する。名前は集約関数と同じにするのがよい *1
- SQLiteから呼ばれるコールバック関数を実装する。関数はnew,step,finalizeのみっつ
- new関数の実装。コンストラクタである。サンプルを書き写すだけで問題ないはず *2
- step関数の実装。この関数はSELECTにてレコードが抽出されるたびに呼ばれる。受け取った引数をblessした配列に追加する *3
- finalize関数の実装。この関数の戻り値が集約関数の結果となる。stepにて配列に追加した要素を元に,値を算出し返す *4
- データベースハンドラのfunc関数を呼び出し,SQLiteに集約関数を追加する *5
- SELECTの例 *6
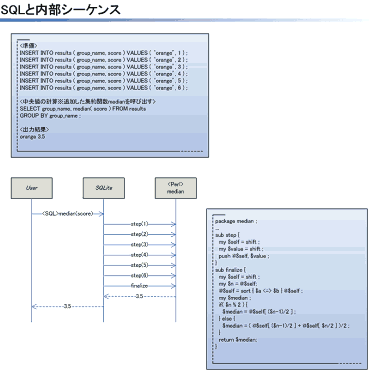
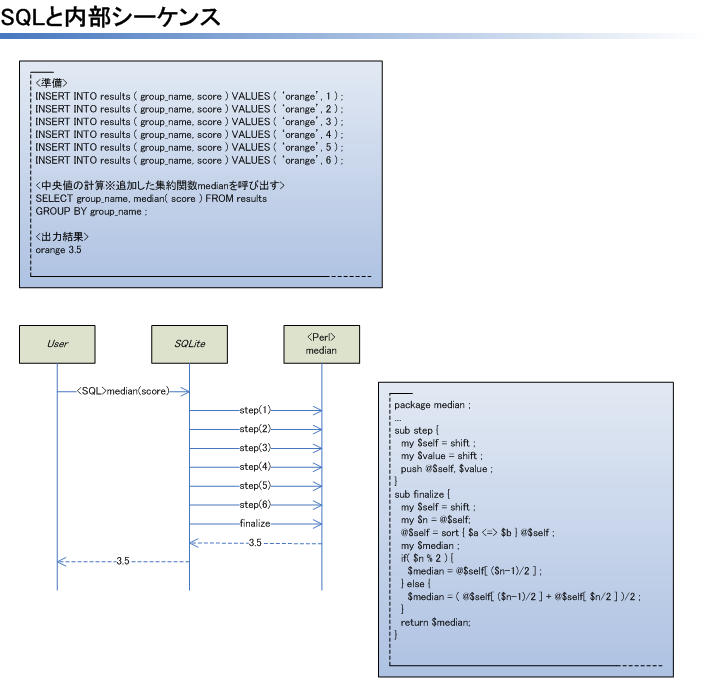
以下,コード例です。コード例はあくまで断片です。変数$dbhにDBハンドラの参照を代入するコードは省略しています。準備としてDBにはresultsテーブルが作成されており,テーブルにはgroup_nameとscoreという列が定義されているものとします。さらには6件レコードが事前に挿入されているものとします。
package median ; # *1
sub new { bless [], shift; } # *2
sub step { # *3
my $self = shift ;
my $value = shift ;
push @$self, $value ;
}
sub finalize { # *4
my $self = shift ;
my $n = @$self;
@$self = sort { $a <=> $b } @$self ;
my $median ;
if( $n % 2 )
{
$median = @$self[ ($n - 1) / 2 ] ;
}
else
{
$median = ( @$self[ ($n - 1) / 2 ] + @$self[ $n / 2 ] ) / 2 ;
}
return $median;
}
# *5
$dbh->func( "median", 1, 'median', "create_aggregate" ) ;
# *6
my $cur ;
$cur = $dbh->prepare( qq!
SELECT group_name, median(score) FROM results
GROUP BY group_name
!) ;
$cur->execute() ;
my $group ;
my $var ;
$cur->bind_columns( undef, \( $group, $var ) ) ;
while( $cur->fetch() )
{
print $group ." " . $var ."\n" ;
}
まとめ
 ⇒大きな画像
⇒大きな画像
{kind=link}
<画像の説明>SQLと内部シーケンスのようなものを図にしました(シーケンスは一部想像です)。stepとfinalizeをだれがいつ呼ぶものなのか分からない人も,図を見れば解決するでしょう。(Microsoft Visioで作成。)
引数がふたつ以上の集約関数
「引数がひとつの集約関数の書き方は分かったけれど,ふたつ以上のときはどうするの?」と思った人がいるかもしれません。3引数の例を以下に書きます。
<step関数>
sub step {
my $self = shift ;
my( $value1, $value2, $value3 ) = @_ ;
push @$self, [ $value1, $value2, $value3 ] ;
}
または
sub step {
my $self = shift ;
push @$self, \@_ ;
}
<finalize関数>
sub finalize {
my $self = shift ;
foreach( @$self )
{
my( $value1, $value2, $value3 ) = ( @$_[ 0 ], @$_[ 1 ], @$_[ 2 ] ) ;
}
...
}
関連リンク
- DBD::SQLite ― 本家の情報です
2006-02-27 携帯電話のUTF-8対応の罠
最近の携帯電話のブラウザ機能はUTF-8に対応しています。UTF-8に対応しているのだからUnicodeのすべての文字を表示できるように思えますが,どうもそうではないようです。
各社の対応状況
国内携帯電話キャリアのUTF-8の対応状況を調べてみました。
DoCoMoのiモードはFOMA 900iシリーズ以降からUTF-8に対応しています。VodafoneはP4(2)型以降(2003年モデル)からUTF-8に対応しています。
auのEZwebだけがUTF-8を扱えません。最新機種でも扱えないようです。
なおPHSのWillcomですがブラウザがOperaの機種はUTF-8に対応しているようです。NetFrontの機種は不明ですがたぶん対応していると思います。【追記 15 MAY 2006】 某氏から報告がありました。NetFrontもUTF-8に対応しているそうです。
取扱説明書を調べてみると
携帯電話でもUTF-8のサイトを表示できるようになってきていると言えるのですが,ひとつ気になることがありました。UTF-8に対応しているからといって,Unicodeのすべての文字を表示できるとはとても思えなかったのです。
フォントの容量の問題もさることながら,フォントには版権があるのです。すべて揃えると,それなりにコスト高になるはずです。「UTF-8に対応していても,じつはSHIFT-JISの範囲内のフォントしか持っていないのでは」と思って調べてみたら予想はだいたい当たっていました。
DoCoMoのWWWサイトからFOMAの取扱説明書(PDF)をダウンロードして,使える文字を調べてみました。付録ページに区点コードの一覧があるのでこいつを眺めれば一発で分かるのです。最近の携帯電話は中国語の漢字にも対応しているらしく,想像していた以上に扱える文字数は多いようです。
しかしながらSHIFT-JISを拡張したような体系であってUnicodeの文字数とは比較にならなかったし,CJK漢字すべてを網羅しているようにも見えませんでした。実際,Acrobatリーダの検索機能を使って一部の旧字を探してみましたが,見つからない文字がありました。
まだまだ調査不足
調査結果を踏まえると,携帯電話のUTF-8対応は「XHTML対応に合わせてUTF-8も解釈できるようにしました」という程度であって「多言語の文字を同じ画面に表示する」というUnicode本来の目的とは違うようです。
まだまだ調査不足です。今回は取扱説明書の区点コードの一覧を見ただけで,実機で表示確認したわけではありません。ほかに気づいたことがあったら続報をお伝えしようと思います。
2006-02-05 J-PHONEだった頃の傷
Vodafone対応サイトを作ってみて気付いたことをお話します。Vodafoneってあまり良い噂を聞かないのですが,関わってみるとこりゃ厄介ですね。
独特の抜けというか癖があるのです。Vodafone対応のコンテンツを作っている業者(の担当者)は,さぞかし嫌な思いをしているのではないかと思います。
以下にお話する内容は,ほとんどがJ-PHONE時代の負債だと思います(世代ごとに検証していないので詳細不明)。最新の機種では改善している機能もあります。
数値文字参照
Vodafoneのブラウザだけが数値文字参照に対応していません。正直にPerlの汎用モジュールを使ってHTMLのメタ文字をエスケープすると,Vodafoneで見たときに「?」みたいなゴミが画面に出てしまいます。
絵文字
驚くべきことに絵文字を入力するときは,エスケープ・シーケンスを使います。[ESC]!nm[SI]ってアレです。DOS時代を知っている人ならピンとくると思います。今って21世紀なのにね。
エミュレータ
ウェブコンテンツヴューア(Vodafone提供のエミュレータ)はユーザエージェント(HTTP_USERAGENT)を送出しません。このためエミュレータでは機種判定の処理を評価できません。
いちばん気になったのは,ウェブコンテンツヴューアの仕上がりです。「ヴューア」という名前のくせになぜかHTMLファイルを編集できます。しかも絵文字の入力支援機能が充実しています。MS-Officeのクリップアートギャラリーに匹敵する仕上がりです。絵文字のエスケープ・シーケンスに拒絶反応を起こす人が大勢いたんでしょうね。ご愁傷様です。
2005-07-31 Excel VBA―その後4―
先週から試作品を運用しています。だいぶ形ができてきました。
準正常系と異常系
準正常系と異常系をまとめています。どちらもエラー処理に関係します。試作品では正常系だけを考慮していました。「エラーはない」「利用者は操作間違いしない」という前提で突っ走っていたわけです。
さて「○○系」などと偉そうなことを言っておいていまさらアレなんですけれど,お恥ずかしながら私,準正常系と異常系の一般的な定義を知りません。復旧できるエラーを準正常系,復旧できないエラーを異常系だと思っているのですが,実際はどうなのでしょう。
例えば「サーバが応答しないとき」は,しばらく待ってから再試行すれば応答するかもしれません。だからこれは準正常系。ただし規定回数,再試行してもやっぱり応答しなかった場合はどうしようもないので異常系。「メモリ不足」は手も足も出ないので問答無用で異常系。というわけで,あながち間違いではないはずですが気になるところです。
【追記 17 FEB 2010】 準正常系って通信関連のソフトウェアで使われる用語「らしい」です。たとえば電話を掛けたときに,「話中」の場合が準正常系だそうです。通信とは関係のないソフトウェアで準正常系って言い方をすると,おかしいのかもしれません。
DBの問題
試作品ではDB(MySQL)との連携を大前提にしています。別途DBがないと動かないのです。でもそれではエンドユーザ向けにしては敷居が高いと思うので,DBなしで動くものに変えるつもりです。
問題はExcelでは大量のデータを裁けないことです。試作品の段階でもレコード数は1日に1万件ずつ増えていきます。Excelはたかだか6万件強のレコードしか裁けないので話にならないのです。元々ExcelはDBではないので,仕方のないことなのです。
もっとも欲しいのは生のデータではなくて,生のデータを統計処理したデータです。統計処理したデータは情報量が少ないのでExcelでも問題なく扱えます。やらなければいけないことは,はっきりしています。生のデータをVBAに処理させるのか,処理させたとして実時間で終わるのか,処理させないなら何が処理するのか,が分かったり決まったりすれば解決できそうです。
2005-07-24 Excel VBA―その後3―
先週,試作品ができました。いま試作品を運用しています。この話題,らいぞうたんとミニラさんしかついて来られない気がするのですが,気にしないで行きましょう(気にしたら負けです←なぞ)。
Excel for Macの文字エンコーディング
ファイル入出力のお話です。MacのVBAで入出力するテキストファイルの文字エンコーディングが何なのか気になっていたのだが,試してみたら「日本語(Mac OS)」でした。
「日本語(Mac OS)」はSHIFT-JISの拡張版で,Macの機種依存文字を網羅した文字エンコーディングのようです。WindowsでいうSHIFT-JISとCP932のような関係なのでしょう。
Mac OS Xって内部はBSDなので,EUCかUTF-8が使われているのではないかと想像していましたが意に反してSHIFT-JIS(の拡張)でした。
Propertyプロシージャに挑戦
独自のクラスモジュールをふたつ作りました。
VBAではクラスモジュールを使うことで,オブジェクト指向でいう「カプセル化」ができます。
クラスが持つ属性の値を変えたいときは,Propertyプロシージャを使うと便利らしい。VBAのPropertyプロシージャは「代入文でオブジェクトに副作用を与えることができる」という代物らしく,使ってみたら「なるほど」という動作をしました。
コレクションにする方法がまだ未調査
クラスモジュールをコレクション(一般にイテレータ:Iteratorと呼ばれているもの)にするにはどうしたらよいのでしょうか。For Each...Next構文を使って,独自に定義したクラスモジュールのインスタンスから繰り返し値を取り出したいのです。
安直に考えるとクラスモジュールに「Collection」というインターフェイスを実装(Implements)すればよい気がします。
でもそんなことがVBAでできるのか,まだ分かりません。分かったら続報をお知らせしようと思います。【追記 1 AUG 2005】現在のVBAでは無理みたいです。なおVB.netだとできるらしい。
2005-07-09 Excel VBA―その後―
先週「Excel VBAで何か作ってます」というお話をしました。途中経過を少々。
諸問題はほぼ解決
週末から検証用の試作品を作っています。最初は,VBAとVBA外の境界線をどこで引けばいいのかさっぱり分かりませんでしたが,だいたいの目処がつきました。
VBA外の問題として,ピボットテーブルの挙動を調査するのが難問なのではないかと想像していたのですが,メーカー提供のチュートリアルをこなしてみたらそうでもありませんでした。数が多く出ているソフトには良い情報がたくさんあるのですね。
BASICの文法に違和感
VBAはVisual Basic for Applicationsという名前のとおりBASIC処理系です(かなり特殊なBASICなのですが,簡単のためひと括りにBASICと言うことにします)。私,BASICを使うのって16年ぶりくらいなものでかなり違和感があります。ついつい文末に;(セミコロン)を付けてしまうのです。余談ですが当時,使っていたのはF-BASIC(富士通FM-77)でした。
VBAでまだよく調べていないのが例外処理です。ON ERRORなんとかを使うのですね。
Excel for Macの扱い
Mac版のExcelでもVBAは動きます。ちょっと試してみると,Windows版と遜色のない動作をするのでびっくりします。でもMac対応は難問だらけです。
Mac版のExcelではコントロール(ボタンやコンボボックスなど)の外観がWindowsと違うのと,フォントも違うのでGUI周りの調節が必要です。致命的なのは,当たり前なんですけどMacではActiveXが使えないのです。ActiveXオブジェクトを生成しようとするとエラーが発生します。
よく言われているように,車輪の再発明は避けなければなりません。もっとも,まだMacのVBAはほとんど調査していないので,意外と簡単に互換性を維持する方法がある,なんて可能性はゼロではありません。何か発見したらお知らせしようと思います。
2005-06-15 URLエンコードされた日本語文字列のデコード
<お急ぎの方は後半の「まとめ」をご覧ください>
概要
Perl5.8のEncodeモジュールを使って,URLエンコードされた日本語文字列をデコードする方法をお話します。
<対象>
- HTTPのGET要求に含まれるURLエンコーディングをデコードしたい人
- サーチエンジンの検索文字列をデコードしたい人
あらまし
最初にバージョン5.8より古いPerlのお話です。URLエンコードされた日本語文字列をデコードするにはどうしたらよいのでしょうか。私が調べたいくつかの書籍では,
$str =~ tr/+/ /;
$str =~ s/%([a-fA-F0-9]{2})/pack( 'C', hex($1) )/eg ;
というコードで最後に文字コードを合わせればよい,なんて記述をよく見かけました。文字コードの変換にはJcode.plがよく使われたようです。
Perl5.8では文字コードの変換に標準対応しており,Jcode.plは不要だそうです。そこで何の気なしに
use Encode ;
my $str ;
$str = '%A4%A2%A4%D9+%A4%DE%A4%EA%A4%A2' ;
$str =~ tr/+/ /;
$str =~ s/%([a-fA-F0-9]{2})/pack( 'C', hex($1) )/eg ;
my $result ;
$result = decode( 'euc-jp', $str ) ;
print $result ;
とするだけで動いてしまうように思えたのですが,実行すると「Wide character in subroutine entry at C:/Perl/lib/Encode.pm line 164.」と怒られてしまいました。
いったいどうすればよいのでしょうか。
解決方法
Perl5.8からUTF-8フラグというものが導入されており,Perlインタプリタ内部では文字列の文字コードをUTF-8として扱っているそうです。
「UTF-8フラグが立っていれば,そのバイト列はUTF-8文字列だけど,フラグが立っていないときは,なんだか知らない」ということなのでしょう。たかが文字列だと思っていたら,どうやらPerlインタプリタ内部では文字列を表すバイト列以外にも情報を持っているようなのです。
結局どうすればよいのかというと,URLエンコードされた文字列をデコードする前に,まずUTF-8フラグを外します。URLデコードが済んだらEncode::decodeで,エンコード前の文字コードを指定します。Encode::decodeが成功すると暗黙でUTF-8フラグが立ちます。
騙されないために
私が「クセモノ」だと思ったのは,UTF-8フラグの挙動です。予期しないところでUTF-8フラグが立ってしまうことがあるのです。例えばUTF-8フラグを外した文字列にtr/+/ /すると,UTF-8フラグが立ってしまいます。
「Wide character in subroutine entry at...」でお悩みの方は,確実にUTF-8フラグの罠に嵌っています。フラグが外れているか,予期しないところでフラグが立っていないか,トレース文を挿入して確認するとよいでしょう。UTF-8フラグの騙しの被害に遭わないように気をつけましょう。
まとめ
以上を踏まえて「%A4%A2%A4%D9+%A4%DE%A4%EA%A4%A2」(エンコード前の文字コードは日本語EUC)をデコードする例を示します。
use Encode ;
my $str ;
$str = '%A4%A2%A4%D9+%A4%DE%A4%EA%A4%A2' ;
$str =~ tr/+/ / ;
$str = encode_utf8( $str ) ; # tr/+/ /後にUTF-8フラグを外すこと
$str =~ s/%([a-fA-F0-9]{2})/pack( 'C', hex($1) )/eg ;
my $result ;
$result = decode( 'euc-jp', $str ) ;
print $result ;
実行すると標準出力に「あべ まりあ」が出力されます。
関連リンク
- Perl 5.8.x Unicode関連 ― Perl5.8のUTF-8のお話
- URLdecoder - URLエンコードされた文字列をデコード ― URLエンコードをデコードするWindowsアプリ
2004-10-18 mixiで時間泥棒の被害にあわないために
あらまし
WindowsプラットフォームのPerlとPerlモジュールを使って,既存のWWWサイトのRSS(RDF Site Summary)を作る手順を簡単に説明します。RSSはサイトの概要を記述したものであり,ウェブログ(Weblog)の見出しによく使われています。
ソーシャルネットワークサービス「mixi」で日記を公開するには,mixi提供の「日記機能」を使うほかにも,よそのWWWサイトの日記にmixiからリンクしてしまうこともできます。これは元々,ウェブログにリンクするためのものですが,インターフェイスさえ合わせればウェブログでなくても構いません。RSSさえ用意できれば,手打ちのHTMLで作ったサイトもmixiの日記の替わりにできるのです。
いまのところmixiには,日記をエクスポートする方法がありません。このことが,どれほど問題なのか気にする人と気にしない人がいると思います。私は「これって時間泥棒かな」と思い(ふめい),その被害に遭わないために外のサイトを再利用してしまうことにしました。
RSSとテンプレート
「あらまし」では「日記っ,日記っ」などと,オモチャ売場で駄々をこねる少女かのように連呼してしまいました。そもそも「日記」って,どんなものなのでしょうか。ここでは,ひとつのHTMLファイルに複数のお話が時系列に並んだものとしておきます。お話には,件名と日付時刻が書かれているものとします。この条件から外れたもの,例えば「ふたつ以上のHTML」や「件名と日付時刻が書かれていないもの」は扱えないものとします。
RSSを作るには,HTMLファイルからひとつひとつのお話の件名,日付時刻を抽出しなければなりません。RSS云々のまえに,HTMLファイルからどうやって必要な情報を抽出するかを考えなければならないのです。
幸いTemplate::ExtractorというPerlモジュールを利用すると,テンプレートでファイルの文章構造を識別し,お目当ての文字列だけを取得することができます。今回,使ったテンプレートを以下に示します。なおテンプレートのメタ文字,構文などの説明は割愛します。
[% ... %] <title> [% wwwtitle %] </title> [% ... %] </h2> <!-- item --> [% FOREACH records %] <h3> [% date_title %] </h3> [% ... %] <!-- item --> [% END %]
さて,HTMLファイルの構造によりますが,テンプレートを適用しただけでは抽出に失敗することが多いです。機械的に生成されたHTMLファイルならまだしも,ひとが書いたコードでは空白や改行の入り方がまちまちだからです。テンプレートを適用するまえに,それらの影響を取り除いておかなければなりませんが,問題解決の考え方はいろいろあると思いますので対応はお任せします。
RSSの生成
HTMLファイルにテンプレートを適用すれば,欲しい部分の文字列を取得することができます。つぎに考えることは,それらの情報からRSSを作ることです。RSSはXMLで記述するので,やることはXMLドキュメントを組み立てることになります。
「親ノードに子ノードをつぎつぎ追加して,ツリーを作ればいいのかしら」
と思った人がいらっしゃると思います。
「それって面倒(びっくりマーク)。createElementとかinsertBeforeとか延々とやるわけ(はてなマーク)簡単にできる方法ないの(はてなマーク)」
と思った人がいらっしゃると思います。
便利なことにXML::RSSというPerlモジュールを使うと,RSSの実体をひとつ生成して,その実体に項目(ハッシュ)をつぎつぎ追加していくことでRSSを作ることができます。XMLは気にしなくても構わないのです。「面倒そうなことが嫌い」「煩わしい関係がイヤ」という思いは万国共通なのです。
つぎに実際にできたプログラム(extract.pl)とRSSファイルを示します。使い方は「perl extract.pl HTMLファイル名 テンプレートファイル名」です。実行すると標準出力にRSSが出力されます。注意したいのは,出力されたファイルの文字エンコードがShiftJISだということです(注意:Windowsは厳密にはShiftJISではなくCP932という文字エンコードだそうです)。文字エンコードを変換する方法はいろいろありますが,私はnkfをパイプで繋いでUTF-8にすることにしました。
extract.pl
#!/usr/bin/perl -w
use strict ;
use encoding 'cp932' ;
use XML::RSS ;
use Template::Extract ;
################################################################################
binmode(STDERR, ':raw :encoding(cp932) ') ;
my $template ;
my $doc ;
open(IN, '<:encoding(cp932)', "$ARGV[0]")
|| die "Can't open html file." ;
$doc = do {
local $/ ;
<IN> ;
} ;
close( IN ) ;
open(IN, '<:encoding(cp932)', "$ARGV[1]")
|| die "Can't open template file." ;
$template = do {
local $/ ;
<IN> ;
} ;
close( IN ) ;
################################################################################
$doc =~ s!\x0d\x0a! !gs ;
$doc =~ s!<!\x0d\x0a<!gs ;
$doc =~ s!>!>\x0d\x0a!gs ;
$doc =~ s!\s*\x0d\x0a!\x0d\x0a!gs ;
$doc =~ s|\x0d\x0a<h3>|\x0d\x0a<!-- item -->\x0d\x0a<h3>|gs ;
$doc =~ s!\x0d\x0a!\n!gs ;
################################################################################
my $obj ;
$obj = (new Template::Extract())->extract( $template, $doc ) ;
my $rss ;
$rss = new XML::RSS( version => '1.0' ) ;
################################################################################
my ($sec, $min, $hours, $mday, $mon, $year) ;
($sec, $min, $hours, $mday, $mon, $year)
= localtime() ;
my $now_iso8601 ;
$now_iso8601
= sprintf( "%04d-%02d-%02dT%02d:%02d:%02d+09:00", $year + 1900, $mon + 1,
$mday, $hours, $min, $sec ) ;
($sec, $min, $hours, $mday, $mon, $year)
= localtime( time() - 5 * 24 * 60 * 60 ) ;
my $offset ;
$offset
= sprintf( "%04d-%02d-%02dT%02d:%02d:%02d+09:00", $year + 1900, $mon + 1,
$mday, $hours, $min, $sec ) ;
################################################################################
my $channel = {} ;
$channel->{ title } = $obj->{ wwwtitle } ;
$channel->{ link }
= "http://www2s.biglobe.ne.jp/~yumi-ii/area_murono/htmlfiles/index.html" ;
$channel->{ dc }->{ date } = $now_iso8601 ;
$channel->{ dc }->{ language } = "ja" ;
$rss->channel( %{ $channel } ) ;
################################################################################
my %mon2mm = (
JAN => 1, FEB => 2, MAR => 3, APR => 4,
MAY => 5, JUN => 6, JUL => 7, AUG => 8,
SEP => 9,
OCT => 10, NOV => 11, DEC => 12
) ;
for ( @{ $obj->{ records }} )
{
my $item = {} ;
my ( $dd, $mon, $yyyy, $hh, $mm, $title ) ;
if ( ( $dd, $mon, $yyyy, $hh, $mm, $title )
= ( $_->{ date_title } =~
/
(\d{1,2})\s
(\w{3})\s
(\d{4})\s
(\d{1,2})
:
(\d{2})
\s?
\x81\x75(.*)\x81\x76
/x
) )
{
#
}
else
{
print "err:$_->{ date_title }" ;
}
my $date ;
$date = sprintf( "%04d-%02d-%02dT%02d:%02d:00+09:00",
$yyyy, $mon2mm{ $mon }, $dd, $hh, $mm ) ;
if ( $offset le $date )
{
$item->{ title }
= substr( "yumi-ii $title", 0, 20 ) ;
$item->{ link }
= "http://www2s.biglobe.ne.jp/~yumi-ii/"
."area_murono/htmlfiles/index.html#hamiyoko" ;
$item->{ dc }->{ date }
= $date ;
$item->{ dc }->{ creator } = "MURONO Bunjin" ;
$rss->add_item( %{ $item } ) ;
}
}
################################################################################
print $rss->as_string ;
# [EOF]
生成されたRSSファイル
よく見ると属性がちょっと足りないみたいです。実用上,差し支えなかったのでそのままにしています。
<?xml version="1.0" encoding="UTF-8"?> <rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#" xmlns="http://purl.org/rss/1.0/" xmlns:taxo="http://purl.org/rss/1.0/modules/taxonomy/" xmlns:dc="http://purl.org/dc/elements/1.1/" xmlns:syn="http://purl.org/rss/1.0/modules/syndication/" xmlns:admin="http://webns.net/mvcb/" > <channel rdf:about="http://www2s.biglobe.ne.jp/~yumi-ii/area_murono/htmlfiles/index.html"> <title> yumi-ii/area_murono </title> <link>http://www2s.biglobe.ne.jp/~yumi-ii/area_murono/htmlfiles/index.html</link> <description></description> <dc:language>ja</dc:language> <dc:date>2004-10-16T02:25:27+09:00</dc:date> <items> <rdf:Seq> <rdf:li rdf:resource="http://www2s.biglobe.ne.jp/~yumi-ii/area_murono/htmlfiles/index.html#hamiyoko" /> <rdf:li rdf:resource="http://www2s.biglobe.ne.jp/~yumi-ii/area_murono/htmlfiles/index.html#hamiyoko" /> <rdf:li rdf:resource="http://www2s.biglobe.ne.jp/~yumi-ii/area_murono/htmlfiles/index.html#hamiyoko" /> <rdf:li rdf:resource="http://www2s.biglobe.ne.jp/~yumi-ii/area_murono/htmlfiles/index.html#hamiyoko" /> </rdf:Seq> </items> </channel> <item rdf:about="http://www2s.biglobe.ne.jp/~yumi-ii/area_murono/htmlfiles/index.html#hamiyoko"> <title>yumi-ii 筋トレの真似3年目</title> <link>http://www2s.biglobe.ne.jp/~yumi-ii/area_murono/htmlfiles/index.html#hamiyoko</link> <dc:creator>MURONO Bunjin</dc:creator> <dc:date>2004-10-15T23:25:00+09:00</dc:date> </item> <item rdf:about="http://www2s.biglobe.ne.jp/~yumi-ii/area_murono/htmlfiles/index.html#hamiyoko"> <title>yumi-ii mixi始めて7日目</title> <link>http://www2s.biglobe.ne.jp/~yumi-ii/area_murono/htmlfiles/index.html#hamiyoko</link> <dc:creator>MURONO Bunjin</dc:creator> <dc:date>2004-10-13T22:25:00+09:00</dc:date> </item> <item rdf:about="http://www2s.biglobe.ne.jp/~yumi-ii/area_murono/htmlfiles/index.html#hamiyoko"> <title>yumi-ii 公衆便所は危険な香り</title> <link>http://www2s.biglobe.ne.jp/~yumi-ii/area_murono/htmlfiles/index.html#hamiyoko</link> <dc:creator>MURONO Bunjin</dc:creator> <dc:date>2004-10-12T19:30:00+09:00</dc:date> </item> <item rdf:about="http://www2s.biglobe.ne.jp/~yumi-ii/area_murono/htmlfiles/index.html#hamiyoko"> <title>yumi-ii mixi始めて5日目</title> <link>http://www2s.biglobe.ne.jp/~yumi-ii/area_murono/htmlfiles/index.html#hamiyoko</link> <dc:creator>MURONO Bunjin</dc:creator> <dc:date>2004-10-11T07:39:00+09:00</dc:date> </item> </rdf:RDF>
気づいたこと
やっていることは難しくないのですが,簡単そうなものに限ってやっかいな罠が潜んでいるものです。気づいたことを挙げておきます。
文字エンコード:古くて新しい問題です。標準入出力はShiftJIS(CP932),Perlのプログラム本体もShiftJISです。XML:: RSSが吐くXMLのエンコードは何になるでしょう。RSSファイルを開いてみると冒頭に「<?xml version="1.0" encoding="UTF-8"?>」なんて書いてあるから,てっきりUTF-8かと思ったら実際はShiftJISのままでした。
データ構造:「ハッシュのハッシュ」が登場します。これは「ハッシュの中にハッシュが入っている」のではなくて,「ハッシュのリファレンスのハッシュ」です(たしか←なぞ)。はじめはデータ構造に悩むかもしれません。間違うと空文字が返ってくるか,未定義値を参照したという警告が実行時に出力されます。
2000-01-29 ポートスキャン入門
近頃インターネット上でのイタズラがちょっとした流行りです。特に中央省庁のサーバが荒らされるという一連の事件は,社会に大きな影響を齎(もたら)しています。NHKのニュースによると,事件の発端はサーバに特殊な信号が発せられたことだったそうです。「特殊な信号」の正体がとても気になりますよね。そこで私も「特殊な信号」を発するプログラムに挑戦してみました*1。
開発ツールには,「最近の出来事 Microsoft Visual J++ 6.0 導入前夜 #1998-1012-01」でもお話したMicrosoft Visual J++ 6.0を使ってみました。マイクロソフト製開発ツールの良いところは,この手のコードを目玉焼きや卵焼きを料理するくらいの手間で作ることができるということです(拍子抜けするくらい簡単だという意味)。

import java.net.Socket;
import java.io.IOException;
public class PortScanner implements Runnable {
String hostname = "127.0.0.1";
int interval = 0;
int startPort;
int endPort;
Thread myThread;
public PortScanner(int start, int end) {
startPort = start;
endPort = end;
myThread = new Thread(this);
}
public PortScanner(String hostname, int start, int end) {
this(start, end);
this.hostname = hostname;
}
public PortScanner(String hostname, int start, int end, int interval) {
this(hostname, start, end);
this.interval = interval;
}
public void start() {
myThread.start();
}
public void stop() {
myThread.stop();
}
public void run() {
////
// この try ブロック,もうちょっとキレイにならないもんかな
////
try {
for (int port = startPort; port <= endPort; port ++) {
System.out.print(port +"...");
try {
Socket s = new Socket(hostname, port);
System.out.println("...OK");
} catch (IOException e) {
System.out.println("NG");
}
Thread.sleep(interval);
}
} catch (InterruptedException e) {}
System.out.println("done.");
}
public static void main(String[] args) {
int interval = 0;
int start = 0;
int end = 1024;
String hostname = "127.0.0.1";
switch (args.length) {
case 4:
interval = Integer.parseInt(args[3]);
case 3:
start = Integer.parseInt(args[1]);
end = Integer.parseInt(args[2]);
case 1:
hostname = args[0];
case 0:
default:
}
System.out.println("target = " +hostname);
System.out.println("start = " +start);
System.out.println("end = " +end);
System.out.println("interval = " +interval +"msec");
System.out.println();
System.out.println("Scanning...");
PortScanner ps;
ps = new PortScanner(hostname, start, end, interval);
ps.start();
}
}
さて,それなりに仕上がったので早速使ってみましょう。私のコンピュータの75番から84番ポートを調べてみます。注意しておきますが,ヨソのサーバホストに特殊な信号を発してはいけませんよ。自称ネットワークの偉い人に怒られます。
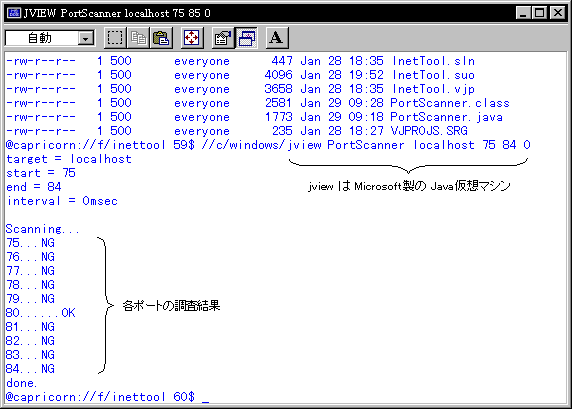
実行結果を見ると80番ポートに陽性反応が出ました。80番ポートは,Webサーバ(HTTPデーモン)の暗黙のポート番号です。つまりポートスキャナは,ローカルに立ち上げているWebサーバを検出したということです。ちなみに検出したからといって,この先どうなるわけでもありません。私もよく知らない(ことにしておく)のですが,はっかーたちは探し当てたポートがどのようなプロトコルを受け付けるのか,引き続き調べていくそうですよ。
プロトコルの挙動を調べるといえばTelnetです。次はTelnetクライアントの製作に挑戦しましょう。
*1 断っておきますが,私は「はっかー」でも「くらっかー」でも「おかき」でもありません。また私の友人にそのような趣味の悪い人は一人もいません。