2006-11-20 クラスター分析ことはじめ―R言語によるシミュレーション―
「クラスター分析ことはじめ」の続報です。前回の話では「まずR言語でクラスター分析してみよう」ということになりました。この度,そのR言語で階層型クラスターを得ることができました。
注:R言語はもっぱら「R」って呼ばれるんですけれど,「R」だけだと何のことなのか分からないので「言語」をあえて添えています。
今回のお題
手掛けた問題を算数の文章題風に書くことにします。
- 「観測地」で観測することのできる「現象」をクラスター分析したいです
- 観測地はたくさんあります
- 現象の種類もたくさんあります
- 観測地によって,発生する現象の種類にはばらつきがあります。たとえば観測地Aでは現象αと現象βが発生します。観測地Bでは現象αと現象γが発生しますが,現象βは発生しません
- 現象が発生する頻度は百分率で表します
便宜上,用語を整理しておきます。
- 「観測地」は「領域」と言い換えることにする
- 「現象」は「個体」と言い換えることにする
MS-Excelでデータを用意する
領域と個体を表にしました。領域dの種類を列方向(横方向)に,個体iの種類を行方向(縦方向)に列記し,領域-個体に該当する値を入力しました。実際には手作業ではなくて表を機械的に作りました。
 ⇒ 全体(容量注意)
⇒ 全体(容量注意)
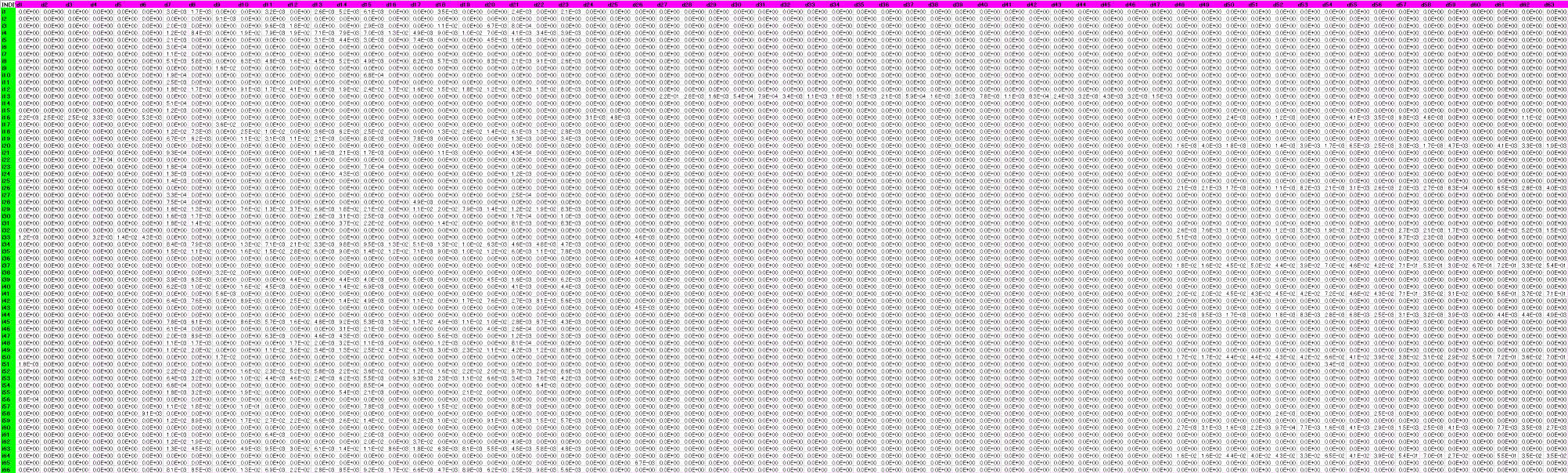{kind=link}
<画像の説明>用意したシミュレーション用のデータの一部です。本番の1/10~1/20の規模です。セルの数値は指数形式になっています。
順位を付与する
領域ごとに個体に順位をつけました。以後は順位を元に解析を進めます。なぜそんなことをしなければならないのでしょうか。このあと個体間の距離を求めるのですが,距離を計算するときに発生頻度の数値を使ったのでは,おかしなことになるからなのです。
じつは領域は各々,規模が異なっており基準を合わせる処理が必要なのです。
順位を正規化する
式 ( r - 1 ) / N により順位を0~1に正規化しました。rは順位,Nは順位の総数です。ただし値が0の要素は特別扱いであり,順位の総数には数えないこととし正規化後は1とすることにしました。
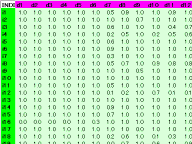 ⇒ 全体
⇒ 全体
{kind=link}
<画像の説明>正規化したデータの一部です。
R言語でクラスター分析する
ようやくR言語の出番です。Excelで作成したデータをファイル保存し,R言語で読み込みました。以下のコマンドにより階層型クラスターを得ました。(R言語はWindows版を使用。バージョンは2.3.1)
library(stats)
x<-read.table("ファイル名",header = TRUE)
attach(x)
mat<-matrix(c(d1,d2,d3,d4,d5,d6,d7,d8,d9,
d10,d11,d12,d13,d14,d15,d16,d17,d18,d19,
d20,d21,d22,d23,d24,d25,d26,d27,d28,d29,
d30,d31,d32,d33,d34,d35,d36,d37,d38,d39,
d40,d41,d42,d43,d44,d45,d46,d47,d48,d49,
d50,d51,d52,d53,d54,d55,d56,d57,d58,d59,
d60,d61,d62,d63),nrow=66)
dis<-dist(mat,method="euclidean")
clus<-hclust(dis)
op<-par(ps=8)
plot(clus,INDIVIDUAL,xlab="",ylab="",sub="")
par(op)
コマンドは長々としています。もっと簡単にできるのかもしれませんが,まだ詳しく調べていないものでこれで勘弁してください。matrix関数は表示の都合で,本来1行で書くべきところを改行しているので注意してください。余談ですがWindowsの場合,ファイル名の指定に注意します。パスの区切り記号は,\ではなく\\を使います。
 ⇒ 大きな画像
⇒ 大きな画像
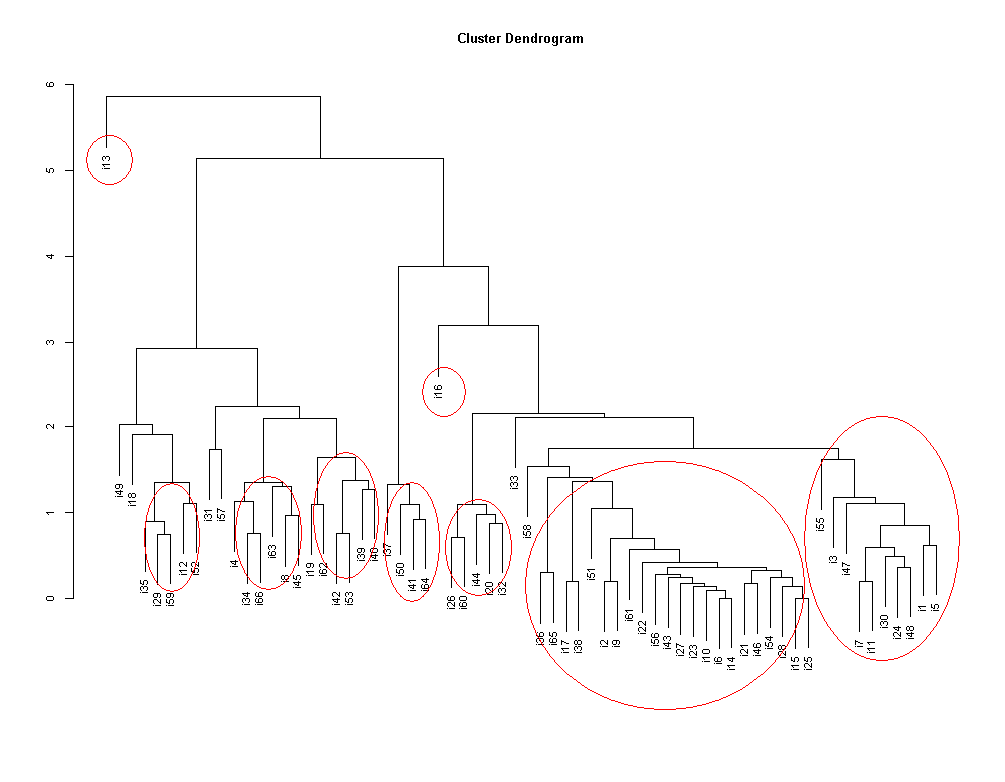{kind=link}
<画像の説明>得られたクラスターの樹状図です。縦軸の数値は個体間の距離(どれだけ似ているか)を表します。赤色の線はあとで付け足したものです。
今後の課題
大雑把にデータを作ったわりに,かなり期待どおりの結果が得られたと思います。しかしながら,まだまだ序の口なのです。検討しなければならないことがいくつかあります。
- クラスターが妥当であると判断する根拠は何か。また妥当でないとするならその根拠はなにか
- 距離の公式にはいろいろある。式を変えた場合,クラスターに変化はあるか。変化するとしたらどのように変化するのか
- 例外値(雑音)が存在するように見える。例外値の除去は可能か。不可能なら影響を小さくする方法はあるか
- 例外値は分析の精度をどれくらい悪化させるのか