 yumi-ii
yumi-ii2009-05-24 遺伝的アルゴリズム事始め
遺伝的アルゴリズムは,最適化手法のひとつです。名前のとおり生物の進化に触発された方法らしく,人工知能と呼ばれるもののひとつだそうです。
上場投資信託(ETF,Exchange Traded Fund)の値動きを分析するために,遺伝的アルゴリズムに挑戦してみることにしました。最近,業界で流行っているみたいですし。(本当なの?)
要件
簡単にソフトウェアの要件を考えてみることにしました。
- 個体数1万×100世代の進化を,実用的な時間でシミュレートできること
- 汎用性を持たせるために,遺伝的アルゴリズムのフレームワークを作成する。フレームワークの上にアプリケーションを実装する
- Windowsプラットフォームに特化する
- 処理系にはVisual J# .NETを使う
静的構造
「やりたいこと」がだいたい決まったところで,ソフトウェアの静的構造を考えてみることにしました。
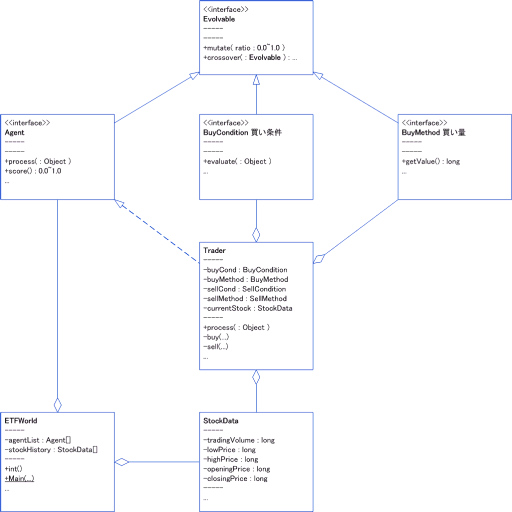
<画像の説明>ソフトウェアの静的構造です。遺伝的アルゴリズムのフレームワークと,上場投資信託を分析するための実装クラスを描きました。(全体構造ではありません。収まりを良くするために,主要なクラスを抜粋して記述しています。)
静的構造の説明を少々。はじめに,遺伝的アルゴリズム特有の事柄を抽象化することにしました。特有の事柄とは,「交叉」「突然変異」「適応度関数」のみっつです。「進化によって個体の状態が変わる」という性質と,個体が持たなければならない性質は細かく分けることにして,各々をEvolvableインターフェイスとAgentインターフェイスに追いやることにしました。
つぎに個体に実行時間を与える方法と,実行時文脈を渡す方法を考えました。これには,Agentインターフェイスの実装クラスのprocess(...)メソッドに実行時のコードを書くという,よく見かける方法を採用することにしました。Javaの世界だとinit(...)の方が好まれそうですが,あえてprocess(...)にしてみました。
今回はシーケンスがさほど複雑ではないので,静的構造が決まったら,9割はできたようなものでした。ほかの細かな点は,実装しながら考えることにしました。
実装
実装には,Visual J# .NET(Visual Studio .NET 2003)を使ってみました。Visual J# .NETを選んだ理由は,手持ちのPCにインストールされていたからです。最初は純粋なJavaを使おうと思っていたのですが,止めました。最近のJavaの開発には,Eclipseという開発ツールを使います。わざわざEclipseをインストールするのは面倒に感じたのと,Eclipseは過去に速度が遅いという評判があったので,軽快に動作するVisual Studio .NET 2003で済ませてしまうことにしました。
気になる実行結果は,「日経225連動型上場投資信託の取引パターン」でお話しています。
今回の目標のひとつは,遺伝的アルゴリズムのフレームワークを作ることでした。出来上がったものを見ると,フレームワークと呼べるほどの汎用性のある構造には仕上がっていないのかもしれません。
個体の表現はクラスであり,クラスを具象化したものがオブジェクトです。よって,「オブジェクトが進化する方法」を考えることになるのですが,オブジェクトが進化するって,どういうことなのでしょうか。
私は,「単純にオブジェクトの内部状態が書き換わること。進化の良し悪しは適応度関数の値が決めることであって,本質的な問題ではない」と考えました。オブジェクトの内部状態を決めるのは,変数です。変数の表現をどうすべきか,最後まで悩みました。実装クラス(Trader)にべったりくっついてしまう結果になりましたが,これが良いのか悪いのか,どうもすっきりしません。
2008-11-08 Excel/Visioでニューラルネットワーク
連休中に多層パーセプトロン型のニューラルネットワークの実験をしました。
「唐突に何言ってるの?ニューラルネットワークって何?」と思った人がいるかもしれません。ニューラルネットワークは,生物の脳の神経細胞を数理的なモデルにしたものだそうです。説明しているサイトは山ほどあるので,興味のある人は検索してみてください。
ニューラルネットワークは,学術的には人工知能のひとつだとされています。人工知能ってコトバは何やら怪しげで,別世界の高度な処理を指しているかのように思えるかもしれません。なんてことはありません。細部を見れば数値を足したり・引いたり,メモリをコピーしたり,処理を条件分岐しているだけです。現在のコンピュータで実現できるのですから,当然なのです。
私は今後,人工知能サービスを整備していくつもりでいます。人工知能と呼ばれているものには数種類ありますが,「ニューラルネットワーク」「制約充足問題」「遺伝的プログラミング」の3本柱をぜひ習得したいと思っています。得られた成果物は,アルゴリズム株取引の売買判定や,アルゴリズム・アフィリエイトの商品の最適化などに使います。
第一弾として,Microsoft Officeにニューラルネットワークを実装してみました。経緯と実験結果をお話します。
準備
じつは私,ニューラルネットワークと無縁だったわけではないのです。学生時代,お向かいの研究室のお題がニューラルネットワークだったのです。何度かそのゼミの研究発表を見ていたので,どんなものなのかはだいたい知っていました。でも当時は大した興味はなくて,「これって何に使うんだろうね」くらいにしか思っていませんでした。
時は流れて2008年,私は自力でニューラルネットワークを実装してみることにしました。今回,主に参考にした本は「臼井支朗」先生らによる「基礎と実践ニューラルネットワーク」です。この本もそうなのですが普通の専門書では,ニューラルネットワークを数式で説明しています。見慣れない用語もいっぱい出てきて,私の能力で理解できるのか心配になってしまいました。以下に,遭遇した専門用語を並べてみますね。
- ニューロンの値
- ニューロンの学習率
- エラー値
- モーメンタム因数
- 重み
- 重み変更係数
- バイアス重み
- バイアス値
最初の難関は「これらの要素が何に属するものなのか」を正確に理解することでした。ニューラルネットワークは,広義にはグラフ(度数分布表のことではなくて「頂点と辺の集合」のこと)です。要素は,「頂点」または「辺」のどれかに属するのです。数式の意味を紐解いて,グラフに当てはめていくことにしました。
つぎの難関は「何をどうやって作るのか,何ができれば良いのか,何をやらないのか」を決めることでした。この手のシステムは,目指すべき世界がはっきりしていないといけません。曖昧なままでは,できたものが役に立たなかったり構造が歪になったりしてしまうのです。要件を箇条書きにします。
- 抽象度を落さない
- 処理速度,メモリ効率は重視しない
- 学習方法には誤差逆伝搬法(バックプロパゲーション法,Error Back Propagation Method)を使う
- 扱うニューロンの数は100未満
- 学習中の過程,学習結果,ニューラルネットワークの特性をグラフィカルに表現・出力できるようにする
- ニューラルネットワークを数式に展開し,Excelで使える関数を出力する機能
Excel VBA/Visio VBAでニューラルネットワーク
ニューラルネットワークの数理的なモデルと,ソフトウェアの要件が分かったような気分になったところで,実装方法を詳しく検討することにしました。
巷には,C/C++言語で書かれたニューラルネットワークのサンプルプログラムが溢れています。これを活用しない手はありません。オライリージャパンの「ゲーム開発者のためのAI入門」と「集合知プログラミング」という本にニューラルネットワークのサンプルプログラムが載っていたので,VBAで実装する際はこれらのコードを参考にすることにしました。
つぎはデータ構造のお話です。たいていのニューラルネットワークのサンプルプログラムは,隣接行列表現(ようは2次元配列)で書かれているようです。私は隣接行列表現ではなくて,隣接リスト表現を採用することにしました。ニューロンとニューロン同士の関係をオブジェクトにして,モデルの抽象度をほどんと変えずに実装することにしました。しかし,データ構造を大胆に変えたがために,入手したサンプルプログラムはほとんど役に立たなくなってしまいました。
どうして,わざわざ遠回りしたのかというと「ニューロンに自律的な振る舞いをさせたい」という思惑があったのです。ニューロンを指して「あなたのいまの値は?」と尋ねれば,値が返ってくるようにしたかったのです。学習中にはニューロンオブジェクトが能動的に描画オブジェクトを書き換えて,ニューラルネットワークの様子をグラフィカルに構築するようにしたかったのです。
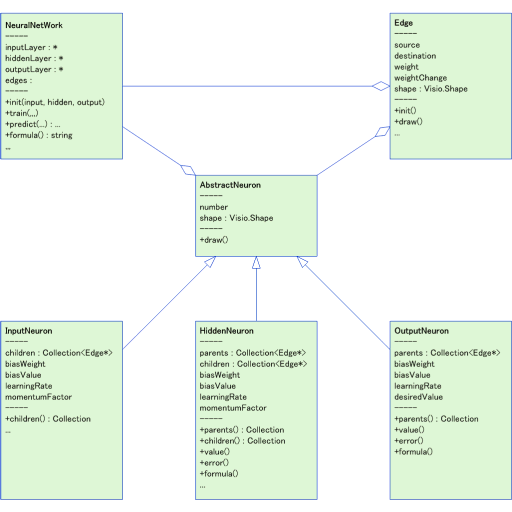
<画像の説明>ソフトウェアの静的構造です。UML風に描いてみましたが,UMLの細かい決まりを意識しているわけではありません。しかも,このままではVBAの言語仕様から逸脱しているのです。実際にはVBAに合わせながら実装しました。
静的構造が決まったところで,Excel VBAで実装してみることにしたのだが,大問題に気づきました。辺(Edge)を表現する描画オブジェクトに「コネクタ」を使っていたのだが,Excelのコネクタにはテキスト属性が存在しないのです。これでは辺の値を表示できません。いやはや調査不足でした。急遽,Visio VBAに載せ替えることにしました。
余談ですが,ExcelとVisioでは描画周りのフレームワークにほとんど共通点がないのですね。派生元の文化の違いを垣間見た気がしました。
XOR問題を解かせてみたら
ソフトウェアが仕上がったので,2入力のXOR(排他的論理和)をニューラルネットワークで解いてみることにしました。
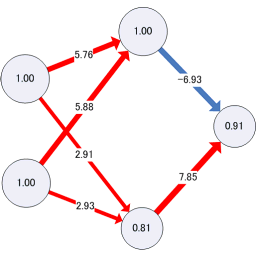
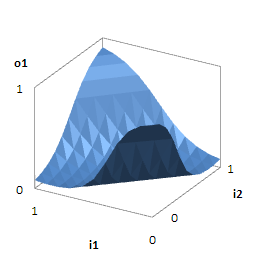
<画像の説明>学習後のニューラルネットワークと,入出力の特性を図にしてみました(ニューラルネットワークはVisio上に半自動で描画されます)。
「普通,XORの入出力は2値なんだから,入出力が連続値(実数)なのはおかしい」と思った人がいるかもしれません。どんな形の関数なのか見たかったので,連続値を入力してみたのです。
「XOR演算できたからといって,何の意味があるの?ニューラルネットワークなんか使わなくても計算できるんじゃないの?」と思った人もいるかもしれません。XOR演算は,この業界の基本例題なのです。例題は例題であって,それ以上の意味はありません。
ついでにニューラルネットワークをVisual Basic相当の式に展開してExcel VBAの関数にしてみました(下のコード)。あまり見かけない形式かもしれません。
Public Function nnxor(i1 As Double, i2 As Double) As Double
Dim h1, h2, o1 As Double
h1 = 1 / (1 + Exp(-(i1 * 5.75629288124718 + i2 * 5.87868353255397 - 2.3117209662348)))
h2 = 1 / (1 + Exp(-(i1 * 2.91199452973333 + i2 * 2.93085382671416 - 4.39555060504074)))
o1 = 1 / (1 + Exp(-(h1 * -6.92972808917433 + h2 * 7.85290876041432 + 2.83947285639982)))
nnxor = o1
End Function
最後に,気づいたことと残された課題を箇条書きにして終わりにします。
- ソフトウェアが正確に仕上がっているのか,十分に検証できていない
- 学習過程をグラフィカルに表現する必要はなかったようです。グラフが書き換わる様子をアニメーションで見られるのは面白いはずだと思っていたのだが,実際にやってみるとネットワークが成熟していくようには見えませんでした。期待外れ
2008-03-20 全文検索システムの導入
SQLiteで実装した日本語全文検索機能をスキャンティ・システムに組み込むことにしました。
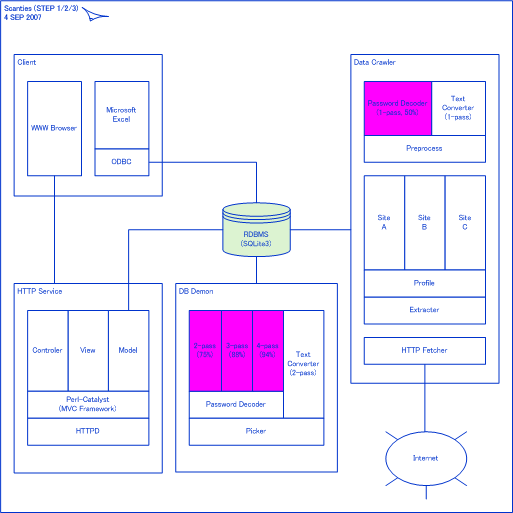
<画像の説明>索引付けをいつするか悩みました。今回は「DBデーモン内のモジュール」として動作させることにしました。インデックサは投稿文のクローラとは非同期に動作します。
「ディメンション(dimension)」という機能ブロックの存在に気付いた人がいるかもしれません。いま方式を検討している新機能なのです。日付ディメンション(date dimension)と位置ディメンション(location dimension)の実装を予定しています。実現すれば時間軸方向および空間方向に伸張圧縮した解析ができるようになります。でも,そのまえにN gramベースの全文検索機能を載せる必要があったのです。
さて,未だにこのシステムの正体が分からない人がいるかもしれません。大別するとOLAP(OnLine Analytical Processing,オンライン分析処理)に分類されます。所詮,SQLiteに載せているので本格的なOLAPの足元にも及ばないとは思いますが,本格的になったときに備えて日々,実験を重ねているのです。
2008-01-23 不正クリックされているようです
「不正クリック?何それ?」と思った人は,さっさとウィンドウを閉じてくださいね(なぞ)。以下,読んでも意味が通じないと思います。
コンテンツマッチ型のネット広告を導入した「ジューシィ」の続報です。どうやら不正クリックされているようなのです。サーバのアクセスログを見てみたら,短期間に同じIPアドレスから何度もクリックされた痕跡が残されていました。悪質なドキュンって底なしなのですね。金額は大したことがないのですが,これでは広告の意味がありません。
「通報しないとだめかしら」と思っていたのだが,いつの間にかクリックされなくなりました。どうも問題のサイトへの広告配信が停止したようなのです。偶然なのか不正クリックが疑われる場合は規制が掛かる仕組みになっているのか,不明ですが,ひとまず危機は回避されました。
2007-09-04 高速パスワード・デコーダ―その後―
高速パスワード・デコーダの続報です。あれから試行錯誤を重ねることで,94%のパスワードを解くことに成功しました。当初は,ぜいぜい8割も解ければよいと思っていたのですが,面白かったのでつい張り切ってしまいました。
ここで,ひとまずパスワードの解読を止めようと思います。これ以上は,ちょっとやそっとでは解けないことが分かってきたのです。これまでの解法をまとめて,システムに組み込むことにしました。
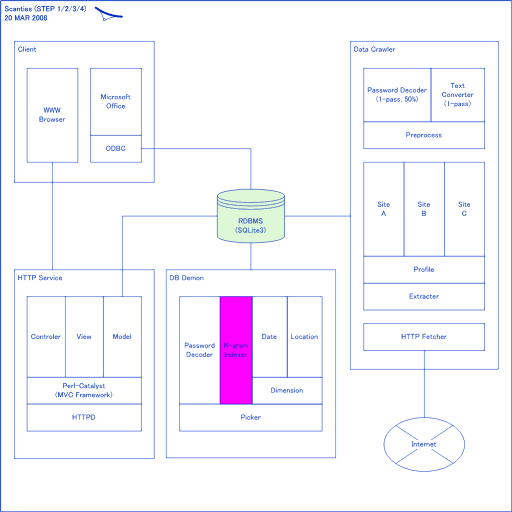
<画像の説明>スキャンティ・システム(STEP1-3)の全体ブロック図です。ソフトウェアの仕組みを他人に説明するのは至難の業ですので,どんな機能があって,それらがどのような関係にあるのか図にしてみました。なお,英単語のような文字の羅列が見受けられますが,適当な語を当てただけなので英語として正しいかどうかは知りません。ラテン文字が使われているからといって,何でもかんでも英語ってわけではありません(←強引な言い訳)。
説明を少々。パスワードの解析は4段階に分けることにしました。1段階では,約50%のパスワードを解くことができます。2段階に進むと約75%のパスワードを解くことができます。段階が進むに連れて,解ける可能性が高くなるようにしたのです(「必ず解ける」というわけではありません)。
また1段階ではデータ取り込み時に,2段階から4段階では「DB Demon」がパスワードを解読するようにしました。「demon(デーモン)」って何かというと,裏で動いているプロセスのことです。定期的に起動するようになっており,データベースの中身を更新していきます。「寝かせておくと情報の質が洗練されていく」という動作をするわけです。
2007-08-16 高速パスワード・デコーダの開発
※この記事では,パスワードを解読する手順を述べています。肝心なことは書かないように配慮していますが,注意してください。
スキャンティ・システム,先月の下旬に全体計画を説明しました。その後,STEP3の実装物にあたるパスワード・デコーダの試作に成功しました。デコーダ(<英>decoder,解読器)の正体はパスワードの一覧表です。現在のパスワード・デコーダは,投稿文の9割を1件当たり0.4秒の速さで解読することができます(プロセッサ:Mobile Athlon XP-M 1800+,クロック周波数:1.2GHzの場合)。
パスワードの解読っていかにも怪しい感じがするのです。業界の人であれば「パスワードを解読するってよく聞く話だけど,実際どうやるの?」と思ったはず。今回,私はパスワードの解読を経て,さまざまな発見をしました。分かったことをすべて書いてしまうと安全上,重大な問題を引き起こしそうです。
そこで内容を吟味し,解読の手順,パスワードの全体傾向,パスワードの望ましい扱い方をお話しすることにします。
解読の手順
世の中に存在する「問題」には,簡単なものから難しいものまでいろいろとあります。パスワードの解読は「難しい問題」のひとつでしょう。なぜ難しいのか。数学的に解釈すると,パスワードの解読は「組み合わせ問題」です。組み合わせの種類は限られているので,「全部試してみればいいじゃん」と思うかもしれませんが,それは無理です。なにしろ試さなければならない数が膨大なのです。「100通り」であるとか「1,000通り」なんて可愛いものではありません。
仮にパスワードが8桁の数字だったとします。1億通りを試さなければなりません。さらに今回,扱うパスワードって,何桁なのか分かりません。全桁が数字とも限らないわけです。そうなると,組み合わせの種類の単位は「億」では済まなくて,「兆」や「京」がつく世界になります。現在のコンピュータはとても高速ですが,それでも簡単に解ける量ではありません。
さて冒頭で,「パスワードの解読は組み合わせ問題だ」とお話しました。たしかにそうなのですが,だからといってすぐに組み合わせを作るための処理の手順を考えたり,プログラムを作ってしまったりするのは早合点というものです。まずパスワードの性質を整理することにします。パスワードを解く鍵は,いつ,だれが,どんな場面で,どのようにして扱うものなのかを把握しておくことなのです。
- 扱うパスワードは人間が思いつく文字列である。機械的な乱数ではない
- 人間には覚えやすい文字の並びと,覚え難い文字の並びがある
- パスワードはキー操作によって入力する。指には関節の構造上,動かしやすい方向と,動かし難い方向が存在する
――これからはすべて,パスワードは必ずしもデタラメというわけではなくて,何らかの規則性が存在することを示唆しています。しかしながら,あくまで仮説です。なんとなくそう思うだけです。どこまで有効なのか,まったく分からないわけですね。ところで,今回のように何から手を付ければ良いのか分からない問題の場合は,仮説を検証して新たな仮説を立てて,その仮説を検証して‥‥という作業の繰り返しになります。
パスワードの全体傾向
前節では「パスワードには何らかの規則性があるはず」という仮説を立てました。さっそく仮説を検証することにしましょう。
検証作業はなるべく簡単な方法を採用すべきです。ひとまず「4桁の数字」という足かせをして,実際にパスワードを解いてみることにしました。みんながみんな4桁の数字をパスワードにしているわけではないのでしょうけれど,何割かは解ける気がしたのです。「木を見て,森を見よう」というわけです。
パスワードが4桁の数字の場合,組み合わせは1万通りあります。今回は1万件の投稿文に対して解読してみることにしました。施行回数は最大で1億回です。実際には,パスワードが解けた投稿文は以後,解読の対象から外れますので施行回数はもっと少なくなります。それでも結果が得られるまで数時間掛かりました。
以下,結果発表です。
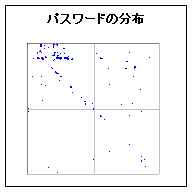
<画像の説明>4桁の数字を上位2桁と下位2桁に分けて,2次元平面上に頻度を描いてみることにしました。点の有無がパスワードの有無に対応します。点が多く集まっている個所と,ほとんどない個所があることが分かりました。対角線上に点が集まっていることに気づいた人がいるかもしれません。これらは「5555」や「7777」のような,ぞろ目の数字です。覚えやすくて,しかも入力しやすい数字の並びだと言えます。
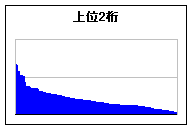
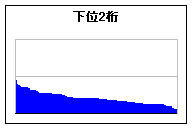
<画像の説明>つぎに上位2桁と下位2桁の数字の出現頻度を,度数分布表にしてみることにしました。中央の目盛線と山の勾配に注目してください。上位2桁は偏りが大きく,下位2桁は偏りが小さいことが分かりました。なぜこんな結果が得られるのか。相変わらず生年月日をパスワードにしている人がいるからなのです。月は1から12,日は1から31。子どもが生まれる月は均一ではないので(真夏や真冬に生まれると育てるのが大変でしょ),パスワードもその影響を受けてしまっているのです。
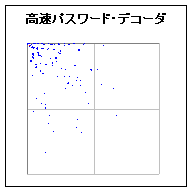
<画像の説明>話は飛びますが,得られた結果から高速デコーダを作ってみました。画像は高速デコーダが出力するパスワードの候補関数の分布です。端折って説明すると,高速デコーダは図の左上の領域は丁寧に調べるけれど,右下はほとんど調べないという動作をします。現在の高速デコーダは,4桁から8桁のパスワードに適用できます。過去に解読したパスワードの一覧,ならびにパスワードの統計的な偏りを利用することで,高速にパスワードを解くことができます。
いま高速デコーダの性能を高めるための準備をしています。やるべきことはすでに見当がついていて,検証作業をしているところです。
パスワードの望ましい扱い方
最後に,破られにくいパスワードのお話をします。今回,解読したのはネット掲示板の削除パスワードなので,バレてしまったからといって実生活への影響はほとんどなさそうです。
ところで銀行のキャッシュカードの暗証番号も,携帯電話のロック番号も,mixiのパスワードも「全部同じ」なんて人はいませんか。そんな人は,掲示板の削除パスワードが解読されてしまっただけで,全財産が脅かされる事態になってしまうのかもしれません。以下,注意点をお話しますので,必要であればパスワードを変えてみてくださいね。私は刺されたいわけでもなければ,他人から呪われたいわけでもないのです。
- パスワードを自分で考えてはいけない。機械的に生成したパスワードを使う
- パスワードを兼用しない
- 中途半端に強い同じパスワードを常用してはいけない。解かれてしまった場合に個人識別を容易にする。非常に危険
――ちなみに「強力なパスワードがほしいけれど思いつかなくて困っている」という方は,「yumi-ii | パスワード文字列を作る」をお試しください。機械的なパスワードが得られます。携帯電話に辞書登録しておけば,複雑なパスワードでも簡単に呼び出すことができますよ。「パスワードをいくつも覚えられないから,つい同じパスワードを使ってしまう」という人は,パスワードを3種類くらい覚えて,サービスの重要度に応じて使い分けるという方法もあるようです。
2007-06-25 エリス―その1―
「エリス(ELIS)」は現在,私が手がけている商品の開発名です。2007年8月の完成を目指しています。
エリスは個人向けのWebサービスです。エリスの肝は利用者管理です。「利用者がログインして何らかの処理後,ログアウトする」といった認証処理を含みます。私,今まで「ログインとログアウト」という仕掛けを手がけた経験がありません。あれこれ下調べに奔走しているのです。
認証と承認
よく「認証」であるとか「承認」という言葉を耳にします。どちらも似たような意味に感じていたのですが,だからといってどちらもはっきりとした意味を把握しておりませんでした。ここで整理しておきましょう。
- 認証 ― ユーザ名,パスワードの整合性を確認する処理
- 承認 ― アクセス権のこと。認証された利用者に許されている操作を特定して,制限を課する処理
エリスでは「承認」はありません。「管理者」「ユーザ」「ゲスト」という区別は存在しないわけです。あえていうなら,すべての利用者はユーザ権限です。
セキュリティ
「セキュリティ(<英>security)」とは,何でしょうか。ヨコ文字にしてしまうと意味が曖昧になってしまうのですが,ここでのセキュリティとは「あらかじめ決めたパスワードを知っている利用者だけが,サービスを使うことができる性質」とします。
実生活で喩えれば,鍵を掛ける行為と一致します。鍵にはいろんな種類があります。銀行の地下金庫からオートロックのマンション,物置の南京錠など,頼りになりそうな鍵から頼りない鍵まであるわけです。地下金庫と南京錠とでは,目指している安全性がまったく違うわけですが,インターネットの世界ではひと括りに「セキュリティ」と言ってしまっている気がします。(ゆえに話が噛み合っていない事例があるように感じます。)
エリスが目指すセキュリティは「南京錠型」です。強力な道具を使われると,壊されてしまう危険があります。しかし鍵の性能は,守らなければならないものの価値に見合ってさえいれば良いはずです。
現在,決まっていることを箇条書きにします。
- 通信経路のプロトコルはHTTPとする。SSLは使わない(技術的な問題もありますが,デジタル署名は高額すぎる。それに法人でなければ取得できなかったような)
- セッション管理にはCOOKIEを使う
- 利用者のパスワードにはダイジェスト値(SHA-1)を使う。サーバホストにてパスワードの平文(生のパスワード文字列)は保存しない
Perl-Catalystによる認証
認証とCOOKIEを使ったセッション管理は,既存のフレームワーク(Catalyst-Plugin-Authenticationモジュール)で実装する予定です。すでにフレームワークの動作検証は済んでいます。
しかしながら,罠がありそうなのです。フレームワークって作者が想定したとおり(もっとはっきり言えばサンプルプログラムどおり)に使っているのなら,何の問題もなく動くことが多いのですが,ちょっと凝ったことをしようとするとたちまち機能不全に陥ることがあります。そもそもフレームワークの範囲内では,実現が不可能な動作も存在するのです。
気にしていることを挙げておきます。
- 認証漏れ ― 認証後でなければ出力してはならないページが,何らかの原因で出力されてしまう現象。原理上,認証漏れが発生しないようにしなければならない
- 同時アクセス ― 同じ利用者(と名乗る利用者)が同一ホストあるいは複数ホスト,複数ブラウザから同時にログインして利用した場合の挙動。内部データはDBで同期を取っているので,深刻な問題は起こらない「はず」だが
- 過渡状態 ― 設計不良あるいはサーバホストの負荷が高く,状態遷移が正常であるにも関わらず,利用者からすると不具合に感じる場合(おもに表示不正)。マズイことが起きたら「ただいま混雑しております」を出力して利用者を制限できるようにしたい。思惑どおり「マズイこと」を検出できたらの話ですが(ふめい)
2006-11-20 クラスター分析ことはじめ―R言語によるシミュレーション―
「クラスター分析ことはじめ」の続報です。前回の話では「まずR言語でクラスター分析してみよう」ということになりました。この度,そのR言語で階層型クラスターを得ることができました。
注:R言語はもっぱら「R」って呼ばれるんですけれど,「R」だけだと何のことなのか分からないので「言語」をあえて添えています。
今回のお題
手掛けた問題を算数の文章題風に書くことにします。
- 「観測地」で観測することのできる「現象」をクラスター分析したいです
- 観測地はたくさんあります
- 現象の種類もたくさんあります
- 観測地によって,発生する現象の種類にはばらつきがあります。たとえば観測地Aでは現象αと現象βが発生します。観測地Bでは現象αと現象γが発生しますが,現象βは発生しません
- 現象が発生する頻度は百分率で表します
便宜上,用語を整理しておきます。
- 「観測地」は「領域」と言い換えることにする
- 「現象」は「個体」と言い換えることにする
MS-Excelでデータを用意する
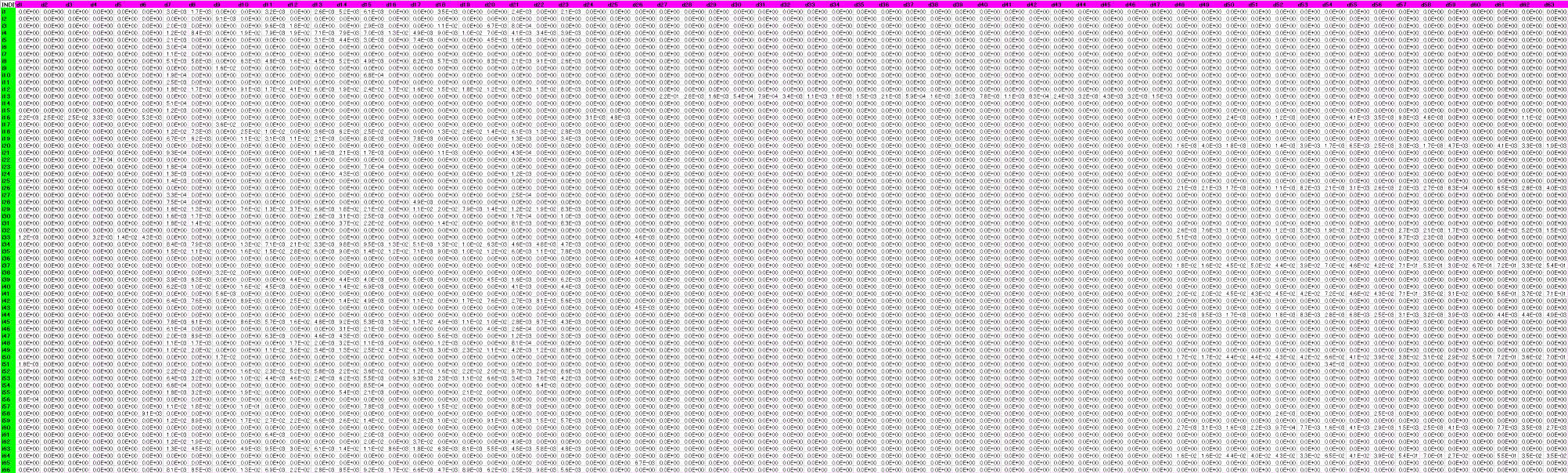
領域と個体を表にしました。領域dの種類を列方向(横方向)に,個体iの種類を行方向(縦方向)に列記し,領域-個体に該当する値を入力しました。実際には手作業ではなくて表を機械的に作りました。
 ⇒ 全体(容量注意)
⇒ 全体(容量注意)
{kind=link}
<画像の説明>用意したシミュレーション用のデータの一部です。本番の1/10~1/20の規模です。セルの数値は指数形式になっています。
順位を付与する
領域ごとに個体に順位をつけました。以後は順位を元に解析を進めます。なぜそんなことをしなければならないのでしょうか。このあと個体間の距離を求めるのですが,距離を計算するときに発生頻度の数値を使ったのでは,おかしなことになるからなのです。
じつは領域は各々,規模が異なっており基準を合わせる処理が必要なのです。
順位を正規化する
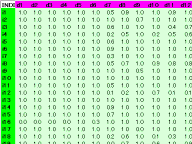
式 ( r - 1 ) / N により順位を0~1に正規化しました。rは順位,Nは順位の総数です。ただし値が0の要素は特別扱いであり,順位の総数には数えないこととし正規化後は1とすることにしました。
 ⇒ 全体
⇒ 全体
{kind=link}
<画像の説明>正規化したデータの一部です。
R言語でクラスター分析する
ようやくR言語の出番です。Excelで作成したデータをファイル保存し,R言語で読み込みました。以下のコマンドにより階層型クラスターを得ました。(R言語はWindows版を使用。バージョンは2.3.1)
library(stats)
x<-read.table("ファイル名",header = TRUE)
attach(x)
mat<-matrix(c(d1,d2,d3,d4,d5,d6,d7,d8,d9,
d10,d11,d12,d13,d14,d15,d16,d17,d18,d19,
d20,d21,d22,d23,d24,d25,d26,d27,d28,d29,
d30,d31,d32,d33,d34,d35,d36,d37,d38,d39,
d40,d41,d42,d43,d44,d45,d46,d47,d48,d49,
d50,d51,d52,d53,d54,d55,d56,d57,d58,d59,
d60,d61,d62,d63),nrow=66)
dis<-dist(mat,method="euclidean")
clus<-hclust(dis)
op<-par(ps=8)
plot(clus,INDIVIDUAL,xlab="",ylab="",sub="")
par(op)
コマンドは長々としています。もっと簡単にできるのかもしれませんが,まだ詳しく調べていないものでこれで勘弁してください。matrix関数は表示の都合で,本来1行で書くべきところを改行しているので注意してください。余談ですがWindowsの場合,ファイル名の指定に注意します。パスの区切り記号は,\ではなく\\を使います。
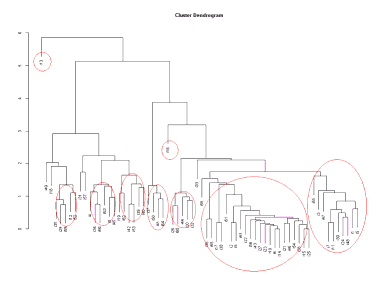 ⇒ 大きな画像
⇒ 大きな画像
{kind=link}
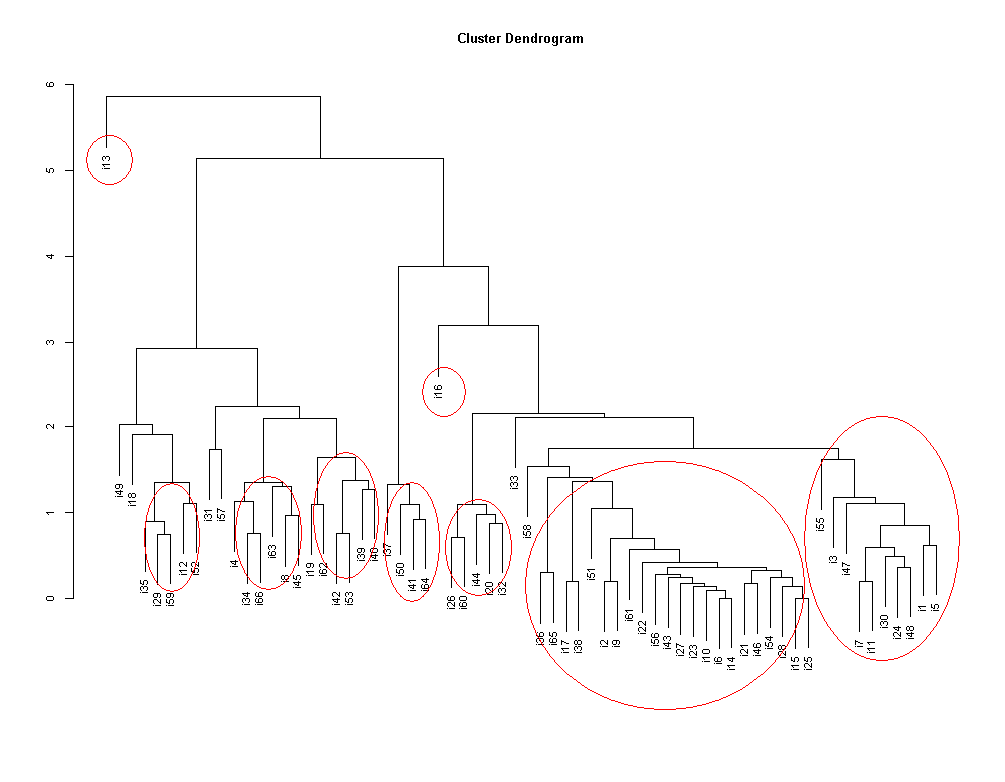
<画像の説明>得られたクラスターの樹状図です。縦軸の数値は個体間の距離(どれだけ似ているか)を表します。赤色の線はあとで付け足したものです。
今後の課題
大雑把にデータを作ったわりに,かなり期待どおりの結果が得られたと思います。しかしながら,まだまだ序の口なのです。検討しなければならないことがいくつかあります。
- クラスターが妥当であると判断する根拠は何か。また妥当でないとするならその根拠はなにか
- 距離の公式にはいろいろある。式を変えた場合,クラスターに変化はあるか。変化するとしたらどのように変化するのか
- 例外値(雑音)が存在するように見える。例外値の除去は可能か。不可能なら影響を小さくする方法はあるか
- 例外値は分析の精度をどれくらい悪化させるのか
2006-11-12 クラスター分析ことはじめ
いま某新製品の準備をしています。詳しい日程は決まっていませんが,来春から来夏あたりに投入できればよいなと思っています。今回のお題の中心(いちばん難しいところ)は「クラスター分析」です。
クラスター分析の正確な定義は知りませんが,「複数の個体から似たもの同士を発見する学問」のようです。その手の業界に足を突っ込んでいる人なら「ああ,あれね」(by 桜庭あつ子←知らない人いるかも)と思ったはずです(ふめい)。
具体的には,数千から数万の個体を階層化したいのです。階層を作るときにクラスター分析が必要というわけです。さて「個体,個体」ってたびたび言いましたが,個体って何のことなのか気になった人がいるかもしれません。扱う個体の正体はヒミツです。
いつものことですが,大学時代の研究とはまったく関係がありません。身近に相談できるような人もいません。大苦戦が予想されるのです。でも既存の技術を丁寧に調べて,実用化にこぎつけられればそれでよいので,道を踏み外さなければ大丈夫な気がします。
これからやることと「思っていること」を少々。
- 個体間の距離を定める方法を考える。いくつか試してみて適応するものを採用
- シミュレーション環境の構築。R言語を使うと便利らしい
- シミュレーションによって,何らかの定数を発見する必要があるような気がする
- シミュレーションが済んだらクラスター分析をモジュール化する
- モジュール化できたらDB,UIをくっつける
- 専門書を何冊か読んでいるので,そのうち感想文のようなものを(私の言う「そのうち」はまるで当てになりません←なぞ)
2006-10-21 ジューシィ2―アフィリエイト崖っぷち―
「ジューシィ」は,アフィリエイトを収益源としたWWWサービスの開発名です。2005年12月下旬から1か月半を掛けて開発,運用を開始しました(現在も運用中)。
ジューシィのその後なのですが,話にならない段階にまで苦戦しています。WWWサーバの運用費分は稼いでいるし,更新は自動なので手間も掛からず赤字にはならないものの,さっぱり売上が伸びないのです。
このままでは,開発費用を回収するだけで何年も掛かってしまいます。アフィリエイトは儲からないって最初から知ってはいましたが,あまりの成績の悪さに「キィーーー」って感じなのです。(実際に「キィーーー」って言っているわけではありませんが←ふめい。)
今後のテコ入れのために問題点を整理しておきます。
サイトの特殊性と商品単価の低さ
WWWサイトというもの,知られていないものはだれも見ません。
ジューシィと似たような内容のサイトがいくつかあるのですが,どこも閑散としているように見えます。そもそも市場規模が小さいようなのです。
普通,アフィリエイトではサイトの内容と掲載する商品の傾向を合わせます。ジューシィの場合,商品単価がかなり低く,売れたとしても利益は1件あたり10円とか20円という世界です。単価が低くてしかも数が出ないのです。
これでは話しになりません。「参入する前に分析しておけよ」と言われてしまいそうなのですが,まったくそのとおりです。いやはや,後の祭りです。
広告配信の問題
ジューシィはPCサイトと携帯サイトのふたつを運用しています。利用数は携帯サイトの方が多いです。PCサイトの3倍くらいあります。
PCサイトの動向は予想の範囲内なので良いとして,問題は携帯サイトです。最初は好調な滑り出しでした。ところが,あれよあれよという間にクリック率が減少していきました。一体,何が起きたのでしょうか。調べてみたら利用者のほとんどがリピータでした。利用者が広告を見慣れてしまったらしく,クリック率が落ちてしまったのです。
リピータの存在はなんら悪いことではありません。まずいのは現在,使っている某社の広告配信システムです。利用者の嗜好を分析して,広告を取っ換え引っ換え配信し続けなければならないのですが,この嗜好の分析の精度が非常に悪いです。どれくらい悪いのか数値化できないくらい悪いです。私はいつも「このヘタレが」と文句を言っています。
アフィリエイトの問題というよりも某社のシステムの限界によるものなのだが,なんとかしたいものです。
今後の対応
- 放っておいても赤字にはならないのでひたすら我慢する ← 不採用。なんらかのテコ入れは必要。今後,成績が悪化する可能性はゼロではない。ただし構いすぎると損をするので注意
- 宣伝を強化する ← 採用
- 広告配信を自前でやる ← 技術的に可能だが現状の費用対効果を考えると時期尚早。規模を拡大できたら再検討
2006-09-20 サラサーティ2―その4―
サラサーティ2の作業を再開しました。なんだかんだ言って6か月間,作業を放置してしまいました。どうも状況が芳しくなかったので,しばらく寝かせてみることにしたのです。味噌や漬物ではありませんが放置しておくと,いい味が出せるものなのです。
時間を置いてみて,いくつか分かったことがあります。諸問題と解決方法の案を整理することにします。
ボトムアップの弊害
まず「設定項目が多すぎる」のをなんとかすることにしました。なぜ複雑になってしまったのでしょうか。しばらく原因に気づけなかったのですが,寝かせてみたら「ボトムアップの弊害なのかも」と気づきました。
サラサーティ2は古いものを土台に,あとから上部をくっつけた格好になっているのです。
サラサーティ2の前にはサラサーティ1がありました。サラサーティ1の前に,さらに原始サラサーティとも言うべき実装物が存在していたのです。サラサーティ開発の動機は,原始サラサーティの動作を表にしたりグラフにしたりして,見やすくすることですので当然といえば当然です。
原始サラサーティは,すでに1年以上の運用実績があります。当初は必要だと思っていたけれど,実際に使ってみたらいらない機能がちらほら。サラサーティ2から,そのいらない機能を取り除き簡略化を図ることにします。
誤った操作に対する耐性の向上
「壊れにくくすること。壊れても修復しやすいこと」をより意識することにします。従来は内部状態が壊れたまま,ずるずると使い続けられるようになっていました。
いちばん気になっていたのは,レコードの識別値にMD5(Message Digest Algorithm 5)を使用していたことでした。MD5の詳しい説明は省略しますが,「3434EF0BCD678D56E9AB78915ACF0122」みたいな文字の羅列を識別値にしていたのです。
一意な値を作るのに便利だったのですが,元のデータが変わると識別値もコロっと変わってしまう性質がありました。元のデータを変えるという操作は通常ではありえないのですが,途中で書き換えられた方が便利なこともあり,そのままにはできなくなりました。
そこで識別値をMD5ではなくて,時間由来の連番値に置き換えることにしました。
ActiveXを積極的に導入
Macintoshプラットフォームの完全な切り捨てを意味します。
ActiveXとはWindows特有のソフトウェアの再利用技術です。当初はMac対応を前提としており,ActiveXを一切使わないで開発を進めていました。ところが後々の調査でMac版のExcel VBAは(Windows版と比べると)性能が低く,関わっていると生産性を損なうことが分かりました。
Mac版のExcelをもっと早い段階で分析しておくべきでした。反省しています。
2006-08-22 ウィスパー3―その5―
ウィスパー3,ただいま試作品(α版あたり)を運用しています。またしてもいろんな問題に遭遇しています。いずれもDBの問題です。
性能が出ない
DBの性能がどうも出なくて困っています。要件では「要求してから応答するまでの時間は3秒以内であること」としています。実際,このとおり動いているのだが,どうも使ってみるとスカッとした使い心地ではないのです。
容量の効率を犠牲にすれば高速化できそうなのですが,そうなると下位サービスを修正しなければいけません。でもすでに稼動しているものを修正するのは嫌なのです。だからといって,このままでいいのかと言うとそれも不満で,両者の板ばさみに遭っております。
特定のクエリで全抽出が発生
ここでの全抽出とは,レコードを抽出する際の条件が機能せず,すべてのレコードを出力してしまう状態を指します。
いろんなクエリを投げてみたのだが,さっぱり応答が返って来ないクエリがあることに気づきました。原因は察しが付いています。特定のクエリでは,抽出条件が空になってしまうはずなのです。全体件数は数百万件あるので,それらをすべて出力しようとすると,とんでもないことになるのです。
この動作は仕様漏れです。仕様はこれから考えることにします。
システムを階層化することの難しさ
諸問題は,ウィスパー3がウィスパー2を土台にしたサービスであることに因ります。ウィスパー2とウィスパー3はDBを兼用しているのです。
実際に稼動させてみると,何やらかみ合わせの悪い歯車のようでお世辞にもうまく行っておりません。ウィスパー2ができた当初,ウィスパー3の仕様はほとんど白紙の状態でしたので後々,不都合が起きるのは当然という気がします。
DBを兼用せずに,独立させるのもひとつの手ですが,そこまではしないつもりです。今の段階では最適ではないというだけで,致命的な不都合は発生していないのです。
私,RDBMSと呼ばれるものを使い始めてまだ日が浅いのですが,この業界はかなり奥が深いと思います。深いどころか底なしなのかもしれませんね。
2006-07-24 ウィスパー3―その4―
ウィスパー3の開発,ようやく終盤戦になってきました。読んでいる人はたぶん一人か二人だと思うので説明がいい加減になってしまいそうですが,はりきっていきましょう。
差の扱いを変更
大掛かりな仕様変更をしました。式の書換えを考えているうちに,どうも現状の仕様ではうまく処理できないことに気づいたのです。
問題は「差」の扱いでした。いままで式が云々という話を散々してきましたが,最終的に何が出力されるのかというと,SQL文が出てくるのです。SQLではそのまんまEXCEPTという演算子が「差」の意味なので,素直に関連付けられると思って何の疑いもなく「差」という演算子を考慮していました。
ところがどうも論理積,論理和,否定で式を処理するのが理に適う気がしてきました。論理演算で差のようなものは,論理積(∩)と否定(¬)で表すことができるはずだからです。そこで「A-B」があったとしたら「A∩¬B」とすることにしました。
書換え規則
論理積(∩),論理和(∪),否定(¬)で表した式をなるべく短くする規則を考えました。以下は書換え規則の一覧です。
| 入力 | 出力 | 備考 |
|---|---|---|
| X∪X | X | R1 |
| X∩X | X | R2 |
| X∪(X∩Y) | X | R3(未実装) |
| X∩(X∪Y) | X | R4(未実装) |
| (X∩Y)∪(X∩Z) | X∩(Y∪Z) | R5(未実装) |
| (X∪Y)∩(X∪Z) | X∪(Y∩Z) | R6(未実装) |
| φ∪X | X | R7 |
| φ∩X | φ | R8 |
| X∪¬X | X | R9 |
| X∩¬X | φ | R10 |
※φは空集合
論理演算の教科書に載っている公式とよく似ています。一部はまったく同じです。おそらく見たことがある人もいると思います。
現在,実装しているのはR1~R2,R7~R10です。R3~R6は実装していません。仕様上,存在するだけです。たぶん出現頻度が低いからです。稼動させてみて頻発するなら実装するつもりです。式の書換えは実行効率をよくするためのものなので,抜けがあっても致命傷にはなりません。
式の書換え
書換え規則を並べてみたところで,これを実際にやるにはちょっとした工夫が必要です。人間の脳みそで考えると「こことここが一緒だから,まとめられる」とか「消せる」と式を見ただけで気づくのですが,現在のコンピュータではそうもいきません。
式は2分木で表しているので,実際にやることは木の枝を切ったりノードを付け替えたりすることです。2分木を使わない方法もありそうですが,思いつきませんでした。
最初に照合元のノード(書換え規則の一覧でいう変数X)を選びます。つぎにX以外のノードについて,おのおの書換え規則と一致するか照合していきます。一致するノードを見つけたら書換え規則に沿って木を書き換えます。
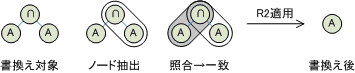
<画像の説明>R2の適用例です。例にしては簡単すぎるのですが,図がないとさっぱり意味が分からないのでつけました。
問題はパターン照合の手間です。今回は「式の長さは最大15項」という制限があるので,木はそれほど大きくなりません。実用的な速さで解けるのですが,どうも小奇麗じゃない気がします。本当にこれで良いのかというと腑に落ちないところがあります。
2006-07-12 ウィスパー3―その3―
だんだんと小難しい話しになってきました。廃刊になったOh!Xに載っていそうな内容になってきましたが,気にしないでください。
式の表現
前回は字句解析と構文解析により,式を表す文字列を因子(<英>factor)に分解しました。もちろん,ただバラバラにしただけではだめです。コンピュータで「式」として扱えるように,なんらかの決まりに則ってデータを格納しなければなりません。
今回は2分木で式を表すことにしました。この方法は定番中の定番です。ちょっと厚めのアルゴリズムの教科書になら,必ず載っています。
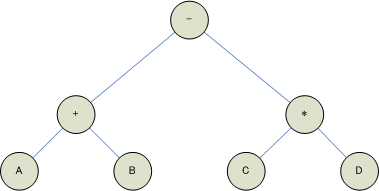
<画像の説明>A+B-C*D(後置記法ではAB+CD*-)の2分木表現。
本来なら2分木の性質や,木を組み立てる前に中置記法で表した式を後置記法に変換する方法にも触れた方がよいのでしょうけれど,細かな説明は省略することにします。業界の人であればだいたい察しが付くはずなのと,目眩がしそうな話しなのでやっぱり触れないでおきます。
BNodeクラスとFactorクラス
データ構造のお話しです。今回は2分木を表すためにBNodeクラスを導入しました(BNodeのBにはBinaryという意味を込めています)。また因子を表現するためにFactorクラスを導入しました。
BNodeクラスならびにFactorクラスには,等価判定とオブジェクトをコピーするための便利なメソッドを付けました。「妙にJavaっぽいな。実装はPerlなんですよね?」と思った人がいるかもしれません。それは何かの錯覚でしょう(ふめい)。
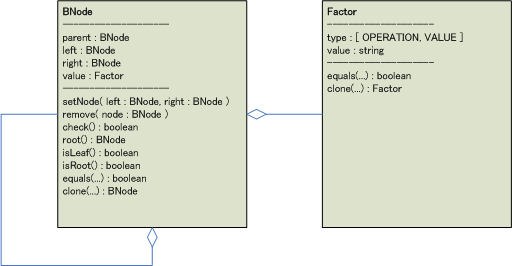
<画像の説明>クラスの定義のようなものです。Microsoft Visioでちょこちょこっと描いてみました。
余談ですが,BNodeのvalueはFactorオブジェクトでなければなりません。クラス間の結びつきが強すぎるのかなと思いましたが,BNodeは汎用的なクラスではないので今回は「良し」としました。
宿題の進み具合
- 式を最適化する ― それらしいものができていますが,停止性の検証がまだ。再帰処理を使ったのですが非再帰に書き換えるつもりです。次回,詳しくお話するつもりです。難易度は高めでした
- 式をSQLに展開する ― それらしいものができています
- 日付時刻の範囲を表すクラス ― まだ調査していません
2006-07-01 ウィスパー3―その2―
今回のお話は,役に立つ人がいそうなので詳しく書きました。意味が分からない人には,怪しげな暗号のように見えるかもしれませんが,気にしないでください。
Perlでyaccを使うには
今回はkmyacc(多言語対応LALRパーサー生成系)を使わせていただきました。kmyaccはPerlにも対応しているのです。
kmyaccを使うには,まずソースファイルをコンパイルして実行ファイルを得なければなりません。WindowsではCygwin環境(Windowsで動作するUNIX系OSの擬似環境)を導入してmakeすれば,実行ファイルを得ることができます。
私,Perlのyacc以前に,素のyaccをまともに使ったことがありませんでした。参考書としてオライリーの「lex&yaccプログラミング」のお世話になりました。いつもの動物本シリーズです。
この本に書かれている例はC言語なのですが,今回使う処理系はPerlです。Perlのお約束と照らし合わせるのにやや苦戦しました。最初はまったくわけが分からなかったので,Cのyaccをまず使ってみて,Perl版との相違を調べることからはじめました。
kmyaccを使ってみて,気づいたことを箇条書きにします。
- yylex関数の中で解析する文字列を読み込み,字句を返す
- 文字列のバッファはyylex関数の外に置く
- 字句の値は$yylval(グローバル変数)に代入する。字句の種類は関数の返り値とする(return文で返す)
詳しくはkmyaccのサンプルプログラムを見れば分かるはず。
ちなみに「Perlのyaccがあるのは分かったけれど,Perlのlexは何処に?」と思った人がいるかもしれません。Perlのlexはどうもなさそうです。今回は字句の解析を自前ですることにしました。
どこまでが字句解析で,どこまでが構文解析か
以下は字句と構文の一般的な話です。kmyaccの話ではありません。
作ってみて,役割分担が曖昧になってしまうのが気になりました。
例えば「1 AND 1」を還元する式を考えてみます。数値と演算子の間には「空白」があるので(また空白で区切らなければいけない,という決まりにしたので),構文は「NUMBER SPACE AND SPACE NUMBER」としても良さそうだし,空白(SPACE)を前処理で取り除いて「NUMBER AND NUMBER」としても良さそうです。
最初は前者の方法を採用していました。でも「空白が2文字以上続いた場合」「前後と末尾に空白がある場合」なども字句と構文で意識しなければならなくなってしまって,どうも「これではうまくいきそうない」と思いました。
参考書(前出の動物本)を読んでみたところ,空白は字句解析の前に処理してしまった方がよいのだそうです。処理手順は「字句解析」「構文解析」の2段階でよいのかと思ったら,どうも字句の解析の前にもう1段階必要だったのです。
文脈の保持
文脈をどうやって扱うのか悩みました。
仮に「2006」という文字の並びがあったとします。これを数値として解釈させるのか,文字列として解釈させるのか,はたまた日付として解釈させるのかは,前後の文脈に依るわけです。
字句解析のコード中に,文脈を保持する変数を導入して,値で場合分けしたらうまく書けました。
今後の課題
以前もお話しましたが,ウィスパー3では集合演算をDB中のレコードに適用します。まだまだ未解決の問題が山積みなのです。
- 式を最適化する ― 式が「A * B + A - A」のようなとき必要なのは「A * B」のみ。「A - A」を計算すると空集合になるので事前に消す
- 式をSQLに展開する ― テンプレートによって式をSQL文に展開する
- 日付時刻の範囲を表すクラス ― 既成のPerlモジュールの存在を調べる。日付時刻範囲オブジェクトt1,t2があったとき,t1.contains(t2)として範囲に「含まれる,含まれない」を真偽値で返したり,t1.concatenate(t2)として範囲を追加・拡張したりできるようなメソッドがあると良い
関連リンク
2006-06-23 ウィスパー3―その1―
ウィスパー3は,ウィスパー2の上位層に位置するアプリケーションです。ウィスパー3の肝は「表の集合演算」と「字句と構文の解析」です。まだ要求仕様と実装仕様のどちらも,はっきりしていません。
表の集合演算
ウィスパー3で定義している集合演算の種類はみっつです。各々,演算子として「+(和)」「*(積)」「-(差)」を使うことにします。例えば以下のように集合A,B,Cがあるとします。
A = { a, b, c, d, e, f }
B = { a, c, d, f }
C = { f }
このとき「A * B - C」は{ a,c,d }です。
(注意:上の例はあくまで考え方を説明するためのものであって,実際にABCやabcdefが出てくるわけではありません。以後もそうです。)
何をやりたいのかというと, SQLのSELECT文で抽出したレコードに対して集合演算したいのです。いったいどうすればよいのでしょうか。
テンポラリテーブルを使った方法
最初に実験したのは,すべて2項演算にしてしまうことでした。A * B - CだったらA * B → Zとして,まずZを求めます。つぎにZ - Cを計算して解を得ます。原理上どんなに長い式でも扱えますし,1回計算するごとに式が短くなるので,数学的に扱いやすいと思いました。以下は擬似コードです。
Clear() ; Calculate( A ) ; Calculate( B, 'AND' ) ; Calculate( C, 'EXCEPT' ) ; Result() ;
(偶然にも命令文の並びは,電子式卓上計算機を操作する手順と似ています。)
2項演算の結果Zは,どこかに残しておかなければいけません。前の計算結果を知らなければ,つぎの計算ができないからです。テンポラリテーブルを作って,途中の計算結果を格納することにしてみたのだが,この方法には問題がありました。
式が長くなると演算回数も増えるので,目に見えて遅くなってしまいました。レコードが数万件のとき,5項の演算で遅い感じがして,15項を超えると使い物にならないという気がしました。要求仕様では,現実的な速さで最大15項の演算ができなければいけません。どうやら考え方が「素直」というだけでは,役に立たないようです。
なぜ遅くなるのでしょうか。項数が増えるとテンポラリテーブルの作成と破棄を何度も繰り返してしまうのと,途中計算のために使いもしないレコードを保持しなければいけないのが原因だと思いました。テンポラリテーブルは1回の演算で使い捨てるので,インデックスとの相性が悪そうなのも気になりました(正確にはインデックスをつけたときの性能を調べていないので不明)。
差の演算回数を1回にした方法
テンポラリテーブルをなるべく使わないで計算する方法を考えたいと思います。以下の案はこれから実験します。
- SELECT文のWHERE句に,複数個のAND演算子とOR演算子を埋め込む
- テンポラリテーブルの出番を1回にする
- 差の演算回数を1回にする
ひとつ目は,例えば「SELECT … WHERE p = α OR p = β AND p = γ AND p = δ」のように,和と積を多項演算してしまいます。
残りのふたつは,同じことを言っています。この方法では,差の演算回数が1回しかありません。仮に「A + B - C - D」という式があったら,変形して「(A + B) - (C + D)」としてしまうのです。
さて何の気なしに「式を変形して」なんて言ってしまいました。コンピュータの世界でこれをするには,まず文字列を字句解析して「演算子」「シンボル(演算されるもの)」に分けなければいけません。つぎに字句の並びを決められた構文に当てはめて,「式」として解釈させなければいけません。簡単にできそうな気もしますが,難しい気もします。
何やらこの先とんでもない罠が待ち構えていそうです。
2006-06-17 ウィスパー2―その5―
ウィスパー2の開発記録,今回が最終回です。
解決した問題点
- 運用サーバの性能に難点 ― その後いろいろやって2.3倍速にできました。サーバの性能と合わせると2.3×1.5=3.4倍速となりました。目標は2倍速だったので作戦大成功なのです
- 初回起動直後のクエリに時間が掛かる ― SELECT文を生で投げてみたら,レコードの抽出速度にムラがある感じ。インデックスをつけたら性能が改善しました
- UNIQUE制約でエラー ― 原因はCTRL+Cではありませんでした。その後も不具合が再発。発生頻度は5万分の1くらいで再現させるのに苦戦。細かくログを出力するようにして網を張ってみたら,原因の捕獲に成功しました。従来の重複チェックでは引っ掛からない箇所で重複レコードが生まれていました。修正したら直りました
運転計画の関数を修正
ウィスパー2には時刻に応じて,サーバホストに掛かる負荷を調節する機能があります。計画段階では時刻を離散値で計算する予定でしたが,連続値で処理することにしました。ただ1次関数で近似しただけですが。実際に動かしてみると適切というか,つなぎ目がなくて滑らかになりました。
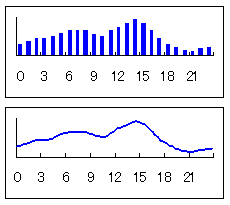
<画像の説明>ウィスパー2で使っている運転計画関数の出力値。上が離散値,下が連続値による算出結果。
ウィスパー3の一部を先行
ウィスパー2の作業は6月末までやるつもりでいました。ちょっと開発を急ぐことにして,6月中にウィスパー3の一部も実装してしまうことにしました。
2006-06-06 ウィスパー2―その4―
DBに試験用のデータを挿入し終えました。ただいま運用時とほぼ同じ環境で,動作検証しています。いつものように,わけの分からない現象に遭遇しています。
運用サーバの性能に難点
実際に運用するサーバで動作試験してみました。思ったほど性能が出ないことが分かったので(開発環境の1.5倍速程度),高速化を図ることにしました。
- キャッシュ ― DBへのアクセスを減らす。DBにアクセスするということは,外部記憶装置(ここではHDD)にアクセスすることになるので性能を低下させる一因になる
- 状態空間の枝狩り ― 容量の削減。あってもなくても性能に影響のない情報を間引く
初回起動直後のクエリに時間が掛かる
DBの容量増大に比例し,DBファイルを開いた直後に発行するクエリに時間が掛かるようになりました。しかも悪いことに減速の度合いは,O(N)ではなくてO(N^2)のように感じます。どういうことかというと,だんだんと遅くなるのではなくて,坂道を転げ落ちるかのように急激に遅くなっていくのです。
遅いのは最初のクエリだけで,2回目以降のクエリは高速です。またDBファイルを開く回数が2回以上のときは,クエリの発行回数に係わらず,どのクエリも高速でした。
この問題は,ディスクキャッシュの影響で発生していると推測しています。回避する方法があるのかないのか,いまのところ不明です。
UNIQUE制約でエラー
DBのテーブルには,「諸条件を満たさないレコードが挿入されようとしたらエラーを返す」という制約をつけています。変なレコードが挿入されて,DBが壊れるのを防ぐためです。
ウィスパー2の一部のテーブル(のカラム)には,UNIQUE制約をつけているのだが,試験運用中に何度かこの制約に引っ掛かり強制停止してしまいました。
テーブルにつけている制約は,実際には未使用です。上位層(アプリケーション側)で重複を調べているので原理上,発生しないエラーのはずなのです。なぜ発生したのでしょうか。「レコードは存在しないけれど,その存在しないレコードのためのインデックスは存在する」みたいな状態になっていたらしい。(詳細な分析はしていないので正確な原因は不明。)
高速化のために同期機能を切っていたのが原因だったようです。DBアクセス中に何度かCTRL+Cで中断していたのだが,あれはやっぱりやってはいけないことだったようです。CTRL+Cを控えるようにしたら,エラーが出なくなりました。
ドキュメントには,同期を切った状態でアプリケーションがクラッシュしてもDBは壊れないと書かれていたのですが,どんな動作を「クラッシュ」としているのか細かく書かれていませんでした。CTRL+Cは想定外のクラッシュなのかもしれません。あるいはOSによって挙動が違うのかも。
2006-05-27 ウィスパー2―その3―
DB層のクラスライブラリはだいたい完成しました。ただいまDBに試験用のデータを挿入しています。かれこれ30時間くらい処理しているはずなのだが,一向に終わる気配がありません。いったいいつになったら終わるのでしょうか。いかんせん試作品なもので,あとどれくらい残っていて,いつ終わるのか表示する機能をつけていないのです。
いつものことですが,量が多すぎて困ってしまいます。途切れることなくディスク・アクセスしているので,HDDが過労で突然死するのではないかと心配してしまいます。(HDDは不定期に交換しているので大丈夫だと思いますが。)
さて「その2」からの進展具合を少々。
- クラスライブラリ ― 実装はほぼ終わりました。それとDBの表の仕様書と,Perlのクラスの仕様書を統一することにしました。別々に作っていたのだが各々,独自の進化を遂げそうだったので阻止しました
- PerlでOOP ― 極端に凝ったことをしていないせいか(「教科書どおり」とも言う),何ごともなく導入できてしまいました
- SQLのトリガ文 ― 意図したとおり動いています。いまのところ問題は発生していません
なにやら順調すぎますね。どこかに罠が仕掛けられているのかもしれません。いつもの勘です(ふめい)。
2006-05-21 ウィスパー2―その2―
ドキュン生活中盤戦,ただいま作業しているのは「ウィスパー2」のII(DB層)です。先週は混沌とした状況でしたが,細かく分析してみたら「すべきこと」が明らかになってきました。
クラスライブラリ
まずクラスライブラリを整備することにしました。DBとDBを使うアプリケーションとのインターフェイスをどうしようか悩みましたが,アプリケーションからはオブジェクトを介してDBを使うことにしました。
オブジェクトを生成してメソッドをがちゃがちゃ呼び出すだけで,DB内のデータを追加・更新・削除できるようにするわけです。
方針は「便利に使えること」を優先するものとします。「アプリケーションからDBの存在を完全に隠蔽する」という考え方もありそうですけれど,DBを隠す必要など最初からないのと,懲りすぎると性能が出なくてハマる気がするので軽く使うことにします。
Perlでオブジェクト指向プログラミング
PerlでOOPです。「ジューシィ」のとき部分的に導入したのですが,ウィスパー2ではもっと積極的に導入することにしました。
Perlでは「@ISA」や「bless」といったキーワードを使って,継承やクラスとクラスのメンバの関連付けをします。
気になったことを少々。
- アクセサメソッドやプロパティのようなものを実装するには ― サブルーチンを定義して,サブルーチン内でblessしたデータ構造にアクセスします。変数の数だけサブルーチンが必要です。数が多くなると書くのが面倒になります。Class::ObjectTemplateモジュールを基底クラスにすると,いくらか簡単に実装できます
- Class::ObjectTemplateが自動作成するアクセサメソッド内で,値の妥当性を評価するには ― できません。できるのかもしれませんが,私はまだその方法を発見していません。というかできないと困るんですけど(なぞ)みなさん,どうやって解決しているのでしょうか
- メソッドをオーバーロードするには ― サブルーチンの引数の数と型を,自前で調べて実装します。同じ名前のサブルーチンを複数宣言することはできません。ウィスパー2では,メソッドをオーバーロードしないで実装しています
SQLのトリガ文
トリガ(TRIGGER)は,ある表のある列が追加・変更・削除される前,あるいはされた後,自動的に実行させるSQL文らしいです。表の整合性を保つために使うと便利そうです。
いままでトリガを使ったことがありませんでした。今回,初導入です。どうなることやら。
関連リンク
2006-04-24 ジューシィ2―その6―
運用中に気づいたことがあったので,またまた手直ししました。
携帯サイトの対象ユーザエージェントを追加
つぎのユーザエージェント(User Agent)を携帯サイトにリダイレクトすることにしました。以下UA名とUAの概要。
- jig browser ― jig.jp社の携帯電話用WWWブラウザ
- NetFront ― ACCESS社の携帯電話・家電用WWWブラウザ
- PlayStation Portable ― いわゆるPSP,ソニーの携帯ゲーム機
.htaccessを修正
ジューシィ2では機種判定を二段階に分けています。まずApacheのMOD_REWRITEを使って,携帯電話やPDAでアクセスしたときは携帯サイトに無理やり誘導します。つぎに「DoCoMo」「AU」「Vodafone」「ほか」のよっつに分けてページ容量と文字コードを変えてページを出力します。
今回の変更は機種判定の第一段階目のみです。.htaccessファイルを修正しました。以下コードです。
RewriteEngine on
RewriteCond %{HTTP_USER_AGENT} DoCoMo [NC,OR]
RewriteCond %{HTTP_USER_AGENT} KDDI- [NC,OR]
RewriteCond %{HTTP_USER_AGENT} UP\.Browser [NC,OR]
RewriteCond %{HTTP_USER_AGENT} J-PHONE [NC,OR]
RewriteCond %{HTTP_USER_AGENT} Vodafone [NC,OR]
RewriteCond %{HTTP_USER_AGENT} MIDP- [NC,OR]
RewriteCond %{HTTP_USER_AGENT} DDIPOCKET [NC,OR]
RewriteCond %{HTTP_USER_AGENT} WILLCOM [NC,OR]
RewriteCond %{HTTP_USER_AGENT} KYOCERA [NC,OR]
RewriteCond %{HTTP_USER_AGENT} Mozilla/3 [NC,OR]
RewriteCond %{HTTP_USER_AGENT} "jig browser" [NC,OR]
RewriteCond %{HTTP_USER_AGENT} "PlayStation Portable" [NC,OR]
RewriteCond %{HTTP_USER_AGENT} NetFront [NC]
RewriteRule !mobile http://www.example.com/mobile/ [R,L]
余談ですが「REWRITE(書換え),CONDITION(制約),RULE(規則)」というのは,グラフ理論の業界で見かける学術用語だった気がします。
気になることをまとめて
- <動作概要>モバイル機器でアクセスしたとき /mobile にリダイレクトする
- フラグNC(no case)は大文字小文字を問わないという意味
- 条件パターン(UA名)は部分一致にしているので予期せぬ動作をする可能性があるが,いまのところ実害はないので細かく記述していない
- すでにmobileにリダイレクトした場合は,処理を終了する(無限ループの防止)。パス名にmobileがどの位置に現れるかまでは判別していないので /.../mobile のような場合に変な動作をしそうだがそれは仕様
関連リンク
2006-03-28 CANDY☆GIRL JAPAN(仮称)
これからある携帯サイトの実験的な試みをしてみようと思います。
ミカのCANDY☆GIRL JAPAN
「ミカちゃん」とは紙媒体による宣伝の実験です。紙媒体という言い方をすると聞こえが良いのですが,早い話がピンクチラシです。チラシをいろんなところにばら撒いてみて,どれほどの効果があるものなのか検証します。
事の発端は「ジューシィ2」の不調にあります。どうもインターネットだけの宣伝では不足であり,ほかの媒体にも手を広げなければならない気がしてきたのです。なおミカちゃんはあくまで実験です。ミカちゃんとジューシィ2には何の関係もありません。

<画像の説明>チラシの試作品です。無味乾燥なチラシに見えるかもしれませんが,実際のチラシではミカちゃんの一言を手書きにして柔らかい雰囲気にします。
検証内容と予定
チラシにより大雑把に検証したい内容を以下に挙げます。
- そもそもチラシを見てアクセスする人なんかいるの?
- 100枚あたりのアクセス数
- 効果的なばら撒き場所
「CANDY☆GIRL JAPAN」はシリーズ化されており毎号ミカちゃんの一言が違います。4月号から7月号の予定を少々。
- 4月号:「ミカがプロデュース!」(創刊号)
- 5月号:「ミカの友達」
- 6月号:「クワガタ虫の飼い方」
- 7月号:「夏体験物語」
- 8月号※自然消滅のためなし
ミカちゃんのプロフィール
仮想人物の設定を挙げておきます。仮想人物の人格を固定しておかないと,一貫した仕上がりにならないのです(そういう問題ではない気がしますが←なぞ)。
- 性格:好奇心が旺盛,社交的
- 活動:学校では新聞局に所属していた。自分だけの情報媒体がほしいと思い立ちCANDY☆GIRL JAPANを創刊
- 年齢:10代
- 性別:設定なし(なぞ)
2006-02-27 ジューシィ2―その5―
ジューシィ2の作業は2月上旬で閉じたのですが一部を手直しすることにしました。携帯サイトで問題が出たのです。
「徳」の旧字が文字化け
「徳」の旧字(Unicode 0x5FB7)が文字化けすることが分かりました。「どうしてかな」と思って調べてみたらSHIFT-JISでは表現できない文字だったのですね。UTF-8からSHIFT-JISに変換できないのが原因でした。なんでも「容易に解決することができない既知の問題」なのだそうです。⇒ http://support.microsoft.com/default.aspx?scid=kb;ja;JP170559
さてどうするか考えました。
- SHIFT-JISから外れた文字は,形の似た文字に置き換える←変換表の準備が大変そうなので却下
- SHIFT-JISから外れた文字を検出して「■(豆腐)」や「〓(ゲタ)」に変換する←妥当な動作のひとつだが文字化けの頻度は極端に低いので却下
- 「既知の問題」として文字化けを容認する←今回はこれを採用
キャッシュコントロールの挙動を変更
HTTPの応答ヘッダで「Cache-control : no-cache」を送るようにしました。この応答を解釈できるブラウザはページをキャッシュしなくなります。
いままでキャッシュ制御していませんでした。試用段階ではキャッシュ制御しなくても使い心地が悪いとは思わなかったのだが,日常的に使ってみると違和感がありました。
ページ容量を変更
1ページの最大容量を縮小することにしました。私が所持している携帯電話(au)の都合なのですが,どうも最大容量ぎりぎりにしてしまうと表示に時間が掛かってイライラしてしまうのです(オラオラではありません←ふめい)。
auのEZwebは絵文字が多いと,表示に時間が掛かる気がします。仕様上,絵文字はローカルリソースの画像として扱っているようなので処理が嵩むのかもしれません。
2006-02-04 ジューシィ―その4―
「ジューシィ」後半は携帯サイトのお話です。すべての機能の実装,公開作業が終わりましたので今回でジューシィのお話は最後です。
動的サイト
ジューシィ携帯版は動的サイトにしました。一般にCGIスクリプトを使ったサイトのことを動的サイトと言います。
試作品では静的サイトだったのだが,どうも作り難いなと思いました。理由はいくつかあります。各社の携帯電話に対応しなければならなかったのと,最短で15分おきに内容を更新しなければならなかったからなのです。でもいちばんの理由は,静的サイトではうまく広告に視線誘導させることができなかったからです。
ページ容量
標準2KB,最大5KBとしました。DoCoMoが推奨しているページ容量と同じです。最近の機種は100KBまで扱えるそうですが,機種を細かく場合分けするのは大変ですし,1ページの文章量が多すぎると読むのが大変になってしまいます。そこで5KBに統一してしまうことにしました。
auとVodafoneはおのおの推奨容量が違うのですが,DoCoMoより5KB多いくらいで大きな違いはありません。
キャッシュの導入
携帯サイトのひとつの山は,ページの分割処理ではないかと思います。携帯サイトでは普通,情報を小分けにして出力しなければなりません。1ページが長すぎると容量過多で受信そのものができなかったり,読む人がうんざりしたりしてしまうからです。
「ページを分ける」というときに,全体を作ってから一部分を切り出すのか,全体が分からなくても一部分を切り出すことができるのかで,性能が大きく違います。(後者の方が性能面で有利です。)
今回の場合,全体を作らなければ一部分を切り出すことができませんでした。このままではいわゆる「重いスクリプト」になってしまいアクセスが増えると500番台のエラーが発生して,サービスが停止してしまう心配がありました。
そこで全体量の計算結果をキャッシュすることで,再計算の回数を減らす工夫をしました。キャッシュ導入以前,実験環境ではひとつのリクエストが完了するまで2秒掛かっていました。キャッシュ導入後は1秒以下になりました。作戦,大成功だったのです。
2006-01-09 ジューシィ―その2―
SQLiteを導入
ジューシィは6時間おきにあるデータを再計算し,HTMLファイルを出力します。いまのところ機能はそれだけですが,将来は何らかのサービスを追加したいと思います。またDB中のレコードは日々,増え続けるため定期的に古いレコードを削除しなければいけません。
いままではデータの管理にBerkley DBを使っていましたが,SQLiteに替えることにしました。「今後の拡張のためにもSQLで操作できるDBを導入した方がよい」という判断をしたためです。
SQLiteはデーモンプロセスが不要なDBです。ひとつのDBはひとつのファイルで完結します。Microsoft Accessが扱うDBのファイルに「mdb」ってありますけれど,あれと発想は同じようです。
SQLiteの第一印象
- ヤダ,「型」がない
- 噂どおり動作は速い
- 短期間の検証では要件を満足することが分かったのだが長期間,使い続けたときの性能が不明。調査する必要がありそうです
相変わらず苦戦中
SQLでも何でもそうですが,しばらく使っていないと忘れてしまうものです。
表を正規化したら,いつつの表に分かれました。DBに表を追加したまでは良かったのだがその後,思考が止まってしまいました。表にレコードを追加するときにサブクエリが必要だったのだが,どうやってSQL文を書けば良いのか分からなくなってしまったのです。
それでもレコードの追加をなんとか終えたのだが,今度は表の結合という最大の難関にぶちあたりました。私どうも表の結合が苦手なのです。いつつの表に用事があったのだが,それらをどうやって組み合わせるか悩んでしまいました。
まず複数のサブクエリが出力した複数の表を結合してみたのだが,とっても性能が悪くなってしまいました。どうやらサブクエリの結果はキャッシュされないようです。結果的にいつつの表を立て続けにガチャガチャ内部結合すれば良いだけでした。いやはやヨコ漏れです。
この先どうなることやら。もちろん何とかしますが(なぞ)。
2006-01-09 ジューシィ―その1―
2005年12月下旬よりサラサーティの開発をお休みしています。替わりに複線の商品を開発しております。11月ごろに思いついたネタです。開発名はなかったのですがさっき決めました。開発名は「ジューシィ」です。
はじめは「ゴージャス」という名前にしようと思いました。でも名前負けすると困るのでやめにしました。勉強嫌いな「マナブ」くん,軟弱な「ツヨシ」くん,恵まれない「メグミ」さんのようではあまりに惨めです。
ジューシィの特徴
- エンドユーザ向けウェブサービス
- 収益源はネット広告(アフィリエイト)
- 運用コストが極めて低い(サーバ・電気料金を含め292円/月)
アフィリエイトは儲からない
ジューシィは昨今,流行りのアフィリエイト(<英>affiliate)を導入したウェブサービスです。(ここではアフィリエイトの詳しい説明は省略します。興味のある人は自分で調べてみてください。)
アフィリエイトというのは,簡単にさまざまな商品を取り揃えることができる反面,収益性は高くありません。簡単であるがゆえに効果もそれなりなのです。一般的なバナー広告の場合,クリック率は0.3%だそうで(3%ではありません)購買に結びつくのはもっと低い確率でしかありません。
早い話がアフィリエイトは儲からないのです。ジューシィではアフィリエイトの特徴を考慮し,利用料金の安価なサーバで大量のアクセスを裁けるように工夫しています。サイト立ち上げとその後の運用に余計な費用を掛けてはいけません。
現在の課題
ジューシィにはPC向けサイトと携帯サイトのふたつがあります。すでにPC向けのサイトはほぼ完成しております。一部の自動化と携帯サイト構築のための調査,設計,実装作業を終えればジューシィの開発はオシマイです。
まだある課題を箇条書きにします。
- [ブラウザ] Geckoエンジン(NN7)だとどうもDOMの操作が鈍く使用感が悪いので修正する
- [永続化] データの永続化にSQLiteを導入する。試作品ではBerkley DBを使っているのだがBerkley DB にはSQLが通じないので,条件をごちゃごちゃくっつけてレコードを抽出したり削除したりしようとすると,手続きが煩雑になってしまう
- [モバイル連携] 携帯電話にURLを通知するためのQRコードの生成方法を調査する
2005-12-19 サラサーティ2―その2―
いろいろ困っています。本当に困っているかどうかはさておき(なぞ)。
Excel2004 for Macにも未対応
Excel2004 for MacのVBA(VBE)もWindowsのExcel97相当なのですね。
ヨドバシの展示機でExcel2004 for Macを弄ってみました。ヘルプにenumが存在しなかったのでまず間違いありません。「Excel2003相当になっているのでは」と期待していたのですが,まったくの見当違いでした。
こうしてサラサーティは晴れてMac非対応となりました。
【追記 24 DEC 2005】Excel 2004のApplication.VBE.Versionを調べてみました。値は「5.0」でした。Excel v. Xも5.0ですので,やっぱりExcel v. XとExcel 2004のVBEは同じものです。
キャッシュが不整合
サラサーティ2ではExcelシートとオブジェクトの変換層にキャッシュを設け,高速化を図っています。どうもこのキャッシュが挙動不審で困っています。Excelブックの読み込み直後と,そのあとでキャッシュの整合が取れていないようなのです。
状態遷移の作り込みが甘いのだと思います。
Excelの仕様に遭遇
TabStripコントロールのchangeイベントハンドラ内で「時間の掛かるある処理」をするとExcel2000が強制終了してしまいました。Excelのバージョンによって動作に違いがありExcel2003では発生しませんでした。
これはExcel2000の仕様なのだと思います。仕様どおりできているのなら,その動作はバグではないのです(ふめい)。どう対処するか考えました。
- 何もしない←現状この動作
- 「古いExcelでは強制終了することがあるので,こまめにファイルを保存してください」という注意を促す←利用者はそんなの知ったことではないので却下
- 画面遷移を変更し仕様を回避する←これを採用